有兩個與人工智能和知識產權相關的巨大問題。 一是內容的使用。 用戶以提示的形式輸入內容,AI 會根據提示執行某些操作。 AI 響應後該內容會怎樣? 另一個是AI對內容的創造。 人工智能使用其算法和訓練數據知識庫來響應提示並生成輸出。 考慮到它已經接受過潛在版權材料和其他知識產權的培訓,輸出的小說是否足以獲得版權?
人工智能對知識產權的使用
AI 和 ChatGPT 似乎每天都出現在新聞中。 ChatGPT,即生成式預訓練變壓器,是 2022 年底推出的 AI 聊天機器人 OpenAI. ChatGPT 使用經過互聯網訓練的 AI 模型。 非營利性公司 OpenAI 目前提供免費版本的 ChatGPT,他們稱之為 研究預覽。 “OpenAI API 幾乎可以應用於任何涉及理解或生成自然語言、代碼或圖像的任務。 “(資源). 除了使用 ChatGPT 作為與 AI 助手(或者, 馬福,一個勉強回答問題的諷刺聊天機器人),它還可以用於:
- 翻譯編程語言——從一種編程語言翻譯成另一種。
- 解釋代碼——解釋一段複雜的代碼。
- 編寫 Python 文檔字符串 – 為 Python 函數編寫文檔字符串。
- 修復 Python 代碼中的錯誤——查找並修復源代碼中的錯誤。
人工智能的快速採用
軟件公司正爭先恐後地將人工智能集成到他們的應用程序中。 ChatGPT 周圍有一個家庭手工業。 有些人創建了利用其 API 的應用程序。 甚至有一個網站自稱是 ChatGPT 提示市場. 他們出售 ChatGPT 提示!

Samsung 是一家看到潛力並加入潮流的公司。 三星的一位工程師使用 ChatGPT 幫助他調試一些代碼並幫助他修復錯誤。 實際上,工程師曾在三個不同的場合將企業 IP 以源代碼的形式上傳到 OpenAI。 三星允許——一些消息人士稱,鼓勵——其半導體部門的工程師使用 ChatGPT 來優化和修復機密源代碼。 在這匹著名的馬被邀請出去放牧之後,三星通過將與 ChatGPT 共享的內容限制在一條推文以下,並調查了參與數據洩露的員工,從而關上了穀倉的門。 它現在正在考慮構建自己的聊天機器人。 (由 ChatGPT 生成的圖像 – 對提示的潛在無意諷刺,如果不是幽默的話,“三星軟件工程師團隊使用 OpentAI ChatGPT 調試軟件代碼,當他們驚訝和恐懼地意識到牙膏從管子裡出來並且他們已經將公司的知識產權暴露在互聯網上”。)
將安全漏洞歸類為“洩漏”可能用詞不當。 如果你打開水龍頭,那不是漏水。 類似地,你在 OpenAI 中輸入的任何內容都應該被視為公開的。 那就是開放人工智能。 它被稱為開放是有原因的。 您在 ChatGpt 中輸入的任何數據都可能“用於改進他們的 AI 服務,或者可能被他們和/或他們的聯盟合作夥伴用於各種目的。” (資源.) OpenAI 確實在其用戶中警告用戶 說明:“我們無法從您的歷史記錄中刪除特定提示。 請不要在談話中分享任何敏感信息,”ChatGPT 甚至在其 回复,“請注意,聊天界面僅供演示,不用於生產用途。”
三星並不是唯一一家將專有、個人和機密信息公開發布的公司。 一項研究 公司 發現從公司戰略文件到患者姓名和醫療診斷的所有內容都已加載到 ChatGPT 中進行分析或處理。 ChatGPT 正在使用這些數據來訓練 AI 引擎並改進提示算法。
用戶大多不知道他們敏感的個人身份信息是如何管理、使用、存儲甚至共享的。 如果一個組織及其係統受到損害,個人數據被洩露、被盜並被用於惡意目的,人工智能聊天中的在線威脅和漏洞將是重大的安全問題。
人工智能聊天的本質是處理和分析包括個人信息在內的大量數據,以產生相關結果。 然而,大數據的使用似乎背離了隱私的概念……(資源.)
這不是對 AI 的控訴。 這是一個提醒。 這提醒我們應該像對待互聯網一樣對待人工智能。 換句話說,將您輸入 OpenAI 的任何信息視為公開信息。 (還要記住,AI 生成的任何輸出都可以進一步轉換或用作為未來用戶生成答案的模型。)這是 AI 損害知識產權和隱私的一種方式。 另一個爭議是人工智能對受版權保護的材料的使用。
人工智能與版權困境
有許多與 AI 合理使用和受版權保護的材料有關的問題。 人工智能能夠處理書面文字。 它可以根據特定的寫作風格總結、分析、分類甚至創建新的內容。 人工智能是根據內容進行訓練的。 我認為它很難避免使用受版權保護的材料。 據我所知,現行法律並未完全解決將受版權保護的內容用於培訓的問題。 (圖片)
我讓 OpenAI 為 Harper Lee 的“殺死一隻知更鳥”的第一頁打字。 它做了。 所以,我很確定它可以訪問受版權保護的文本。 然後它可以創建哈珀李風格的簡歷。 或者,您可以要求它根據本書的主題創作一首十四行詩。
| 莎士比亞十四行詩
基於“殺死一隻知更鳥”的主題 在梅科姆鎮,正義似乎是一個夢想, 小童子軍和傑姆發現了超越他們年齡的真相。 他們的父親,阿提克斯,一個高貴的主題 他們的道德指南針引導他們克服恐懼。 湯姆·羅賓遜,一個被誣告的黑人, 否認一個聲音,一個公正和公平的審判。 但阿迪克斯為他辯護,並不覺得好笑, 因為真理和正義必須是我們的事。 反舌鳥,純潔優雅的象徵, 無害,它的歌曲帶來和平。 但邪惡潛伏在這個小鎮的空間裡, 正義隨著仇恨開始增加而下降。 Harper Lee 的話,對我們所有人的警告, 為正義而戰,以免我們倒下。 |
|---|
這不可能與莎士比亞的作品或哈珀李的作品相混淆。 它是變革性的新內容,顯然不要與原始內容混淆。 出現了幾個問題。 它在什麼時候變成轉型? 換句話說,原始作品需要更改多少才能被視為新內容?
另一個問題——這同樣適用於 AI 創建的任何內容——誰擁有它? 誰擁有內容的版權? 或者,作品甚至可以受版權保護嗎? 可以說版權的所有者應該是製作提示並向 OpenAI 提出請求的個人。 圍繞即時創作有一個新的家庭手工業。 在某些在線市場上,您可以支付 2 到 20 美元的費用以獲得計算機生成的藝術作品或書面文字的提示。
還有人說它應該屬於OpenAI的開發者。 這引發了更多問題。 它取決於用於生成響應的模型或引擎嗎?
我認為最有說服力的論點是計算機生成的內容不能受版權保護。 美國版權局在 聯邦公報,2023 年 XNUMX 月. 其中指出,“由於該辦公室每年收到大約 XNUMX 萬份註冊申請,它看到了註冊活動的新趨勢,可能需要修改或擴展申請中披露的信息。” 它繼續說,“這些技術,通常被描述為‘生成人工智能’,引發了這樣的問題:它們生產的材料是否受版權保護,由人類創作和人工智能生成的材料組成的作品是否可以註冊,以及什麼尋求註冊的申請人應向辦公室提供信息。”
“辦公室”承認,將一項已有 150 年曆史的法律應用於還未滿一周年的技術存在一些問題。 為了解決這些問題,版權局發起了一項研究該問題的倡議。 它將就如何解決在人工智能訓練中使用受版權保護的內容以及如何考慮生成的內容進行研究並公開徵求公眾意見。
聯邦公報, 有點令人驚訝的是,提供了一些色彩評論並描述了一些與作品的“作者身份”及其版權歷史政策相關的有趣案例。 一個被裁定的案件認為猴子不能擁有版權。 在這種特殊情況下,猴子用相機拍攝圖像。 法院裁定這些圖像不能獲得版權,因為版權法提到了作者的“孩子”、“寡婦”、“孫子”和“鰥夫”。 在法庭看來,這種語言排斥猴子。 “該辦公室現有的註冊指南長期以來一直要求作品是人類創作的產物。”
當 OpenAI 被問及爭議時,它說,“是的,在軟件和人工智能方面,知識產權法存在灰色地帶。 由於技術的複雜性和缺乏既定的法律先例,通常很難確定創作者對其作品擁有哪些權利。 例如,如果人工智能算法是基於小說或現有軟件程序,那麼誰擁有算法或原創作品的權利並不總是很清楚。 此外,人工智能相關發明的專利保護範圍是一個有爭議的法律問題。”
OpenAI 在這一點上是正確的。 很明顯,美國的版權申請必須具有人類作者身份。 從現在到年底,版權局將嘗試解決一些遺留問題並提供額外指導。
專利法與人工智能
圍繞美國專利法及其是否涵蓋人工智能發明的討論也是類似的情況。 目前,根據法律規定,可獲得專利的發明必須由自然人做出。 美國最高法院拒絕審理對這一概念提出質疑的案件。 (資源.) 與美國版權局一樣,美國專利商標局正在評估其立場。 美國專利商標局可能決定使知識產權所有權更加複雜。 人工智能的創造者、開發者、所有者可能擁有它幫助創造的發明的一部分。 非人類可以成為部分所有者嗎?
科技巨頭谷歌最近也加入了進來。 “‘我們認為,根據美國專利法,人工智能不應被標記為發明者,並且認為人們應該對在人工智能幫助下實現的創新持有專利,’谷歌高級專利顧問勞拉·謝里丹 (Laura Sheridan) 表示。” 在谷歌的聲明中,它建議增加對人工智能、工具、風險和專利審查員最佳實踐的培訓和意識。 (資源.) 為什麼專利局不採用使用人工智能來評估人工智能?
人工智能與未來
人工智能的能力,事實上,整個人工智能領域在過去 12 個月左右的時間裡發生了變化。 許多公司希望利用 AI 的力量,並獲得更快、更便宜的代碼和內容所帶來的好處。 企業和法律都需要更好地理解技術在隱私、知識產權、專利和版權方面的影響。 (由 ChatGPT 生成的帶有人類提示“AI and the Future”的圖像。注意,圖像不受版權保護)。
更新:17 年 2023 月 XNUMX 日
每天都有與人工智能和法律相關的發展。 參議院設有隱私、技術和法律司法小組委員會。 它正在舉行一系列關於人工智能監督:人工智能規則的聽證會。 它打算“編寫人工智能的規則”。 小組委員會主席參議員理查德布盧門撒爾表示,目標是“揭開這些新技術的神秘面紗並對其負責,以避免過去的一些錯誤”。 有趣的是,在會議開始時,他播放了一段深度偽造的音頻,克隆了他的聲音,其中包含根據他之前的言論訓練的 ChatGPT 內容:
很多時候,我們已經看到當技術超過監管時會發生什麼。 對個人數據的無節制利用、虛假信息的氾濫以及社會不平等的加深。 我們已經看到算法偏見如何使歧視和偏見長期存在,以及缺乏透明度如何破壞公眾信任。 這不是我們想要的未來。
它正在考慮一項建議,即根據食品和藥物管理局 (FDA) 和核管理委員會 (NRC) 模型創建一個新的人工智能監管機構。 (資源.) AI 小組委員會的一位證人建議,AI 應該像 FDA 監管藥品一樣獲得許可。 其他目擊者將 AI 的當前狀態描述為充滿偏見、幾乎沒有隱私和安全問題的狂野西部。 他們將西方世界的機器描述為“強大、魯莽且難以控制”的反烏托邦。
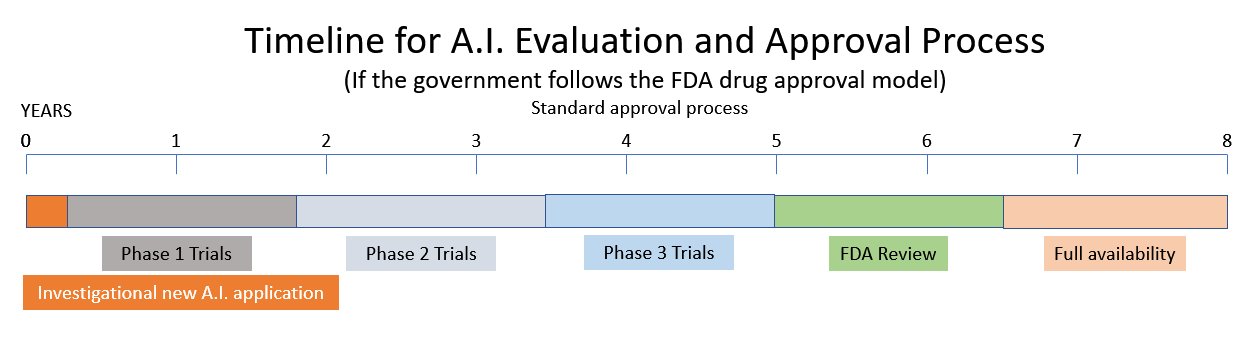
將一種新藥推向市場需要 10-15 年和 XNUMX 億美元。 (資源.) 因此,如果政府決定效仿 NRC 和 FDA 的模式,請期待最近人工智能領域激動人心的創新海嘯將在不久的將來被政府監管和繁文縟節所取代。






.jpg){kind=link}