AI: Pandora's Box of Ynnovaasje
In lykwicht fine tusken it oplossen fan de nije fragen dy't AI opropt en de foardielen fan ynnovaasje
D'r binne twa enoarme problemen yn ferbân mei AI en yntellektueel eigendom. Ien is it gebrûk fan ynhâld. De brûker fiert ynhâld yn yn 'e foarm fan in prompt wêrop de AI wat aksje útfiert. Wat bart der mei dy ynhâld neidat AI reagearret? De oare is de skepping fan ynhâld fan AI. AI brûkt syn algoritmen en kennisbasis fan trainingsgegevens om te reagearjen op in prompt en útfier te generearjen. Sjoen it feit dat it is oplaat op potinsjeel auteursrjochtlik beskerme materiaal en oare yntellektuele eigendom, is de útfierroman genôch foar auteursrjocht?
AI's gebrûk fan yntellektueel eigendom
It liket derop dat AI en ChatGPT alle dagen yn it nijs binne. ChatGPT, of Generative Pre-trained Transformer, is in AI chatbot lansearre ein 2022 troch OpenAI. ChatGPT brûkt in AI-model dat is oplaat mei it ynternet. It non-profit bedriuw, OpenAI, biedt op it stuit in fergese ferzje fan ChatGPT dy't se de ûndersyk preview. "De OpenAI API kin tapast wurde op praktysk elke taak dy't it ferstean of generearjen fan natuerlike taal, koade of ôfbyldings omfettet. "(Boarne). Neist it brûken Chat GPT as in iepen konversaasje mei en AI-assistint (of, Marv, in sarkastyske petearbot dy't fragen mei tsjinsin beantwurdet), kin it ek brûkt wurde om:
- Oersette programmeartalen - Oersette fan de iene programmeartaal nei de oare.
- Koade útlizze - Ferklearje in yngewikkeld stik koade.
- Skriuw in Python docstring - Skriuw in docstring foar in Python-funksje.
- Fix bugs yn Python-koade - Fyn en reparearje bugs yn boarnekoade.
De rappe oanname fan AI
Softwarebedriuwen besykje AI yn har applikaasjes te yntegrearjen. D'r is in cottage yndustry om ChatGPT. Guon meitsje applikaasjes dy't har API's brûke. D'r is sels ien webside dy't himsels as in ChatGPT prompt merkplak. Se ferkeapje ChatGPT-prompts!

Samsung wie ien bedriuw dat seach it potinsjeel en sprong op 'e bandwagon. In yngenieur by Samsung brûkte ChatGPT om him te helpen wat koade te debuggen en him te helpen de flaters te reparearjen. Eigentlik uploaden yngenieurs by trije aparte gelegenheden bedriuws-IP yn 'e foarm fan boarnekoade nei OpenAI. Samsung tastien - guon boarnen sizze, oanmoedige - syn yngenieurs yn 'e semiconductor divyzje te brûken ChatGPT te optimalisearjen en reparearje fertroulike boarne koade. Nei't dat sprekwurdlike hynder útnoege waard nei de greide, sloech Samsung de skuorre doar ticht troch ynhâld dield mei ChatGPT te beheinen ta minder dan in tweet en it personiel te ûndersykjen dat belutsen wie by it gegevenslek. It besjocht no it bouwen fan in eigen chatbot. (Ofbylding generearre troch ChatGPT - in mooglik ûnbedoeld iroanysk, as net humoristysk, antwurd op 'e prompt, "in team fan Samsung-software-yngenieurs dy't OpentAI ChatGPT brûke om softwarekoade te debuggen as se mei ferrassing en ôfgryslik beseffe dat de toskepasta út 'e buis is en se hawwe yntellektueel eigendom fan bedriuwen bleatsteld oan it ynternet.)
It klassifisearjen fan de befeiligingsbrek as in "lek" kin in misnomer wêze. As jo in kraan draaie, is it gjin lek. Analogysk moat elke ynhâld dy't jo ynfiere yn OpenAI as iepenbier wurde beskôge. Dat is OPEN AI. It hjit iepen foar in reden. Alle gegevens dy't jo ynfiere yn ChatGpt kinne brûkt wurde "om har AI-tsjinsten te ferbetterjen of kinne wurde brûkt troch har en / of sels har alliearde partners foar in ferskaat oan doelen." (Boarne.) OpenAI warskôget brûkers yn har brûker guide: "Wy binne net yn steat om spesifike prompts út jo skiednis te wiskjen. Diel asjebleaft gjin gefoelige ynformaasje yn jo konversaasjes," ChatGPT omfettet sels in warskôging yn har reaksjes, "Tink derom dat de petearynterface bedoeld is as in demonstraasje en net bedoeld is foar produksjegebrûk."
Samsung is net it ienige bedriuw dat proprietêre, persoanlike en fertroulike ynformaasje yn it wyld frijlit. In ûndersyk bedriuw fûn dat alles fan bedriuwsstrategyske dokuminten oant nammen fan pasjinten en medyske diagnoaze wie laden yn ChatGPT foar analyse of ferwurking. Dy gegevens wurde brûkt troch ChatGPT om de AI-motor te trenen en de promptalgoritmen te ferfine.
Brûkers witte meast net hoe't har gefoelige persoanlike identifisearjende ynformaasje wurdt beheard, brûkt, opslein of sels dield. Online bedrigingen en kwetsberens yn AI-petearen binne wichtige feiligensproblemen as in organisaasje en har systemen kompromitteare binne, de persoanlike gegevens wurde lekke, stellen en brûkt foar kweade doelen.
De aard fan AI-chatten is om in grutte hoemannichte gegevens te ferwurkjen en te analysearjen, ynklusyf persoanlike ynformaasje, om relevante resultaten te produsearjen. It gebrûk fan grutte gegevens liket lykwols ôf te diverjen fan it konsept fan privacy ...(Boarne.)
Dit is gjin oanklacht fan AI. It is in herinnering. It is in herinnering dat AI moat wurde behannele as it ynternet. Mei oare wurden, beskôgje alle ynformaasje dy't jo yn OpenAI feed as iepenbier. (Tink ek dat elke útfier generearre troch AI fierder kin wurde omfoarme of brûkt as model om antwurden te generearjen foar takomstige brûkers.) It is ien manier wêrop AI yntellektuele eigendom en privacy kompromittearret. In oare kontroversje is it gebrûk fan AI fan auteursrjochtlik beskerme materiaal.
AI en it auteursrjochtdilemma
D'r binne in oantal soargen relatearre oan AI earlik gebrûk en auteursrjochtlik beskerme materiaal. AI is yn steat om it skreaune wurd te ferwurkjen. It kin gearfetsje, analysearje, kategorisearje en sels nije ynhâld meitsje op basis fan in bepaalde skriuwstyl. AI wurdt trainearre op ynhâld. Ik tink dat it dreech wêze soe om it konsumearjen fan auteursrjochtlik beskerme materiaal te foarkommen. Foar safier't ik wit, giet de hjoeddeistige wet it gebrûk fan auteursrjochtlik beskerme ynhâld foar training net folslein oan. (Byld)
Ik frege OpenAI om de tekst te typen foar de earste side fan "To Kill a Mockingbird" fan Harper Lee. It die. Dat, ik bin der wis fan dat it tagong hat ta de auteursrjochtlik beskerme tekst. It kin dan in resume meitsje yn 'e styl fan Harper Lee. Of jo kinne it freegje om in sonnet te meitsjen basearre op it tema fan it boek.
| In Shakespearean Sonnet
Basearre op it tema fan "To Kill a Mockingbird" Yn Maycomb syn stêd dêr't gerjochtichheid liket in dream, Young Scout en Jem fine wierheid bûten har jierren. Harren heit, Atticus, in aadlik tema Waans morele kompas har troch har eangsten liedt. Tom Robinson, in swarte man falsk beskuldige, In stim wegere, in rjochtsaak dat rjochtfeardich en earlik is. Mar Atticus ferdigenet him, net amusearre, Want wierheid en gerjochtichheid moatte ús saak wêze. De spotfûgel, in symboal fan reine genede, Unskuldich fan skea bringt syn liet frede. Mar it kwea leit yn 'e romte fan dizze lytse stêd, En gerjochtichheid falt as haat begjint te fergrutsjen. Harper Lee's wurden, in warskôging foar ús allegear, Om te fjochtsjen foar gerjochtichheid, dat it net ús fal is. |
|---|
D'r is gjin kâns dat dit fersinne sil mei Shakespeare's wurk - of Harper Lee's foar dy saak. It is transformational nije ynhâld dúdlik net te betiizjen mei it orizjineel. Ferskate fragen komme op. Op hokker punt wurdt it transformaasje? Mei oare wurden, hoefolle moat it orizjinele wurk feroare wurde om it as nije ynhâld te beskôgjen?
In oare fraach - en dit jildt likegoed foar elke ynhâld makke troch AI - wa hat it? Wa hat it auteursrjocht op de ynhâld? Of kin it wurk sels auteursrjochtlik beskerme wurde? In argumint kin wurde makke dat de eigner fan it auteursrjocht it yndividu moat wêze dy't de prompt makke en it fersyk fan OpenAI makke. D'r is in nije cottage-yndustry om prompt skriuwen. Op guon online merkplakken kinne jo tusken $ 2 en 20 betelje foar prompts dy't jo komputer-genereare keunst as skreaune tekst krije.
Oaren sizze dat it moat hearre ta de ûntwikkelder fan OpenAI. Dat ropt noch mear fragen op. Hinget it ôf fan it model of de motor dy't wurdt brûkt om it antwurd te generearjen?
Ik tink dat it meast twingende argumint dat moat wurde makke is dat ynhâld generearre troch in kompjûter kin net auteursrjochtlik beskerme wurde. De US Copyright Office útjûn in ferklearring fan belied yn 'e Federal Register, maart 2023. Dêryn stiet, "Om't it buro elk jier sawat in heal miljoen oanfragen foar registraasje ûntfangt, sjocht it nije trends yn registraasjeaktiviteiten dy't it feroarjen of útwreidzjen fan 'e ynformaasje dy't nedich is om te iepenbierjen op in applikaasje nedich wêze kinne." It giet fierder om te sizzen, "Dizze technologyen, faak omskreaun as 'generative AI', rope fragen op oer de fraach oft it materiaal dat se produsearje wurdt beskerme troch auteursrjocht, oft wurken besteande út sawol troch de minske skreaun as AI-generearre materiaal meie wurde registrearre, en wat ynformaasje moat wurde levere oan it buro troch oanfregers dy't se besykje te registrearjen."
"It buro" erkent dat d'r fragen binne relatearre oan it tapassen fan in 150 jier âlde wet op technology dy't har earste jierdei net sjoen hat. Om dy fragen oan te pakken, lansearre it Copyright Office in inisjatyf om it probleem te bestudearjen. It sil ûndersykje en iepen foar iepenbier kommentaar oer hoe't it it gebrûk fan auteursrjochtlik beskerme ynhâld moat oanpakke yn 'e training fan AI, lykas hoe't it de ynhâld moat beskôgje dy't wurdt generearre.
De Federal Register, wat ferrassend, biedt wat kleur kommentaar en beskriuwt in oantal nijsgjirrige gefallen yn ferbân mei de "authorship" fan wurken en syn histoaryske belied op copyright. Ien saak dy't beoardiele waard holden dat in aap gjin auteursrjocht kin hâlde. Yn dit bysûndere gefal namen apen bylden mei in kamera. De rjochtbank oardiele dat de ôfbyldings net auteursrjochtlik beskerme koenen, om't de Copyright Act ferwiist nei de ''bern'''''widdo''''pakesizzers'' en ''widower' fan in auteur. Yn 'e eagen fan 'e rjochtbank hat dizze taal apen útsletten. "De besteande registraasjebegelieding fan it Office hat lang easke dat wurken it produkt binne fan minsklik auteurskip."
As OpenAI wurdt frege oer de kontroversje, seit it: "Ja, d'r binne grize gebieten fan rjochten op yntellektueel eigendom as it giet om software en AI. Fanwegen de kompleksiteit fan 'e technology en it ûntbrekken fan fêststelde juridyske precedinten, is it faak lestich om te bepalen hokker rjochten in skepper hat op har wurk. Bygelyks, as in AI-algoritme basearre is op in roman of in besteande softwareprogramma, is it net altyd dúdlik wa't de rjochten hat op it algoritme of it orizjinele wurk. Derneist is de omfang fan oktroaibeskerming foar AI-relatearre útfinings in kontroversjele juridyske kwestje. ”
OpenAI hat hjir gelyk op. It is dúdlik dat in Amerikaanske oanfraach foar auteursrjocht minsklik auteurskip moat hawwe. Tusken no en it ein fan it jier sil it Copyright Office besykje guon fan 'e oerbleaune fragen op te lossen en ekstra begelieding te jaan.
Patentwet en AI
Diskusjes oer US Patent Law en oft it útfinings beslacht makke troch AI is in ferlykber ferhaal. Op it stuit, lykas de wet is skreaun, moatte oktroaibere útfinings makke wurde troch natuerlike persoanen. It Supreme Court fan 'e Feriene Steaten wegere in saak te hearren dy't dat begryp bestride. (Boarne.) Lykas it Amerikaanske Copyright Office evaluearret it US Patent and Trademark Office syn posysje. It is mooglik dat de USPTO beslút om eigendom fan yntellektueel eigendom komplekser te meitsjen. De AI-skeppers, ûntwikkelders, eigners kinne in diel hawwe fan 'e útfining dy't it helpt te meitsjen. Koe in net-minsk diel-eigner wêze?
De techgigant Google hat koartlyn weage. "'Wy leauwe dat AI net moat wurde bestimpele as in útfiner ûnder de Amerikaanske oktroaiwet, en leauwe dat minsken oktroaien moatte hawwe op ynnovaasjes dy't mei help fan AI makke wurde," sei Laura Sheridan, senior patintadviseur by Google. Yn 'e ferklearring fan Google advisearret it ferhege training en bewustwêzen fan AI, de ark, de risiko's en bêste praktiken foar oktroaiûndersikers. (Boarne.) Wêrom nimt it oktroaiburo it gebrûk fan AI net oan om AI te evaluearjen?
AI en de takomst
De mooglikheden fan AI en, yn feite, it heule AI-lânskip binne feroare yn 'e lêste 12 moannen, of sa. In protte bedriuwen wolle de krêft fan AI brûke en de foarstelde foardielen fan rapper en goedkeaper koade en ynhâld rispje. Sawol bedriuw as de wet moatte in better begryp hawwe fan 'e gefolgen fan' e technology as it relatearret oan privacy, yntellektueel eigendom, oktroaien en auteursrjocht. (Ofbylding oanmakke troch ChatGPT mei minsklike prompt "AI en de takomst". Opmerking, ôfbylding is net auteursrjochtlik beskerme).
Update: 17 mei 2023
D'r bliuwe elke dei ûntjouwings yn ferbân mei AI en de wet. De Senaat hat in rjochterlike subkommisje foar privacy, technology en de wet. It hâldt in searje harksittings oer tafersjoch op AI: Regel foar keunstmjittige yntelliginsje. It is fan doel "de regels fan AI te skriuwen." Mei it doel "om dy nije technologyen te ûntmystisearjen en te ferantwurdzjen om guon fan 'e flaters fan it ferline te foarkommen," seit foarsitter fan 'e subkommisje, senator Richard Blumenthal. Ynteressant, om de gearkomste te iepenjen, spile hy in djippe falske audio dy't syn stim klone mei ChatGPT-ynhâld trained op syn eardere opmerkingen:
Te faak hawwe wy sjoen wat der bart as technology de regeljouwing oertreft. De ûnbeheinde eksploitaasje fan persoanlike gegevens, de proliferaasje fan disinformaasje, en it ferdjipjen fan maatskiplike ûngelikens. Wy hawwe sjoen hoe't algoritmyske foaroardielen diskriminaasje en foaroardielen kinne behâlde en hoe't it gebrek oan transparânsje it fertrouwen fan it publyk kin ûndergrave. Dit is net de takomst dy't wy wolle.
It beskôget in oanbefelling om in nij Regulatory Agency foar Artificial Intelligence te meitsjen basearre op modellen fan 'e Food and Drug Administration (FDA) en de Nuclear Regulatory Commission (NRC). (Boarne.) Ien fan 'e tsjûgen foar de AI-subkommisje suggerearre dat AI fergunning soe moatte wurde fergelykber mei hoe't pharmazeutika wurde regele troch de FDA. Oare tsjûgen beskriuwe de hjoeddeistige steat fan AI as it Wylde Westen mei gefaren fan bias, bytsje privacy en feiligensproblemen. Se beskriuwe in West World dystopia fan masines dy't "machtige, roekeloos en lestich te kontrolearjen."
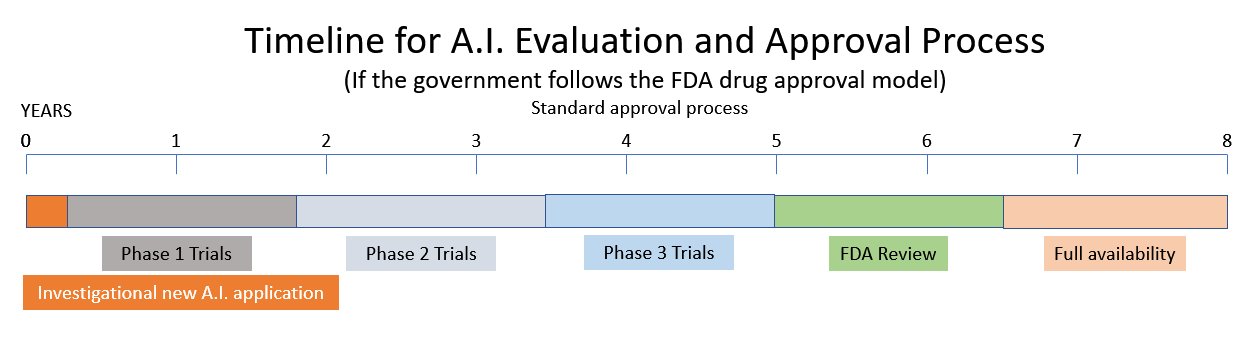
Om in nij medisyn op 'e merk te bringen nimt 10 - 15 jier en in heal miljard dollar. (Boarne.) Dus, as de regearing beslút om de modellen fan 'e NRC en FDA te folgjen, sykje dan nei de resinte tsunami fan spannende ynnovaasje op it mêd fan Artificial Intelligence dy't yn' e heulende takomst ferfongen wurde troch regearingsregeling en red tape.






.jpg){kind=link}