ដូចដែលអ្នកបានដឹងហើយថា ក្រុមការងាររបស់ខ្ញុំ និងខ្ញុំបាននាំយកផ្នែកបន្ថែមកម្មវិធីរុករកទៅកាន់សហគមន៍ Qlik ដែលរួមបញ្ចូល Qlik និង Git ដើម្បីរក្សាទុកកំណែផ្ទាំងគ្រប់គ្រងដោយរលូន បង្កើតរូបភាពតូចៗសម្រាប់ផ្ទាំងគ្រប់គ្រងដោយមិនចាំបាច់ប្តូរទៅបង្អួចផ្សេងទៀត។ ក្នុងការធ្វើដូច្នេះ យើងរក្សាទុកអ្នកអភិវឌ្ឍន៍ Qlik ចំនួនពេលវេលាដ៏សំខាន់ និងកាត់បន្ថយភាពតានតឹងប្រចាំថ្ងៃ។
ខ្ញុំតែងតែស្វែងរកមធ្យោបាយដើម្បីកែលម្អដំណើរការអភិវឌ្ឍ Qlik និងធ្វើឱ្យទម្លាប់ប្រចាំថ្ងៃប្រសើរឡើង។ នោះហើយជាមូលហេតុដែលវាពិបាកពេកក្នុងការជៀសវាងប្រធានបទដែលបំភាន់បំផុត ChatGPT និង GPT-n ដោយ OpenAI ឬ Large Language Model ដូចគ្នា។
ចូររំលងផ្នែកអំពីរបៀបដែលគំរូភាសាធំ, GPT-n, ដំណើរការ។ ផ្ទុយទៅវិញ អ្នកអាចសួរ ChatGPT ឬអានការពន្យល់របស់មនុស្សដ៏ល្អបំផុតដោយ Steven Wolfram ។
ខ្ញុំនឹងចាប់ផ្តើមពីនិក្ខេបបទដែលមិនពេញនិយម "GPT-n Generated Insights from the data is a Curiosity-Quenching Toy" ហើយបន្ទាប់មកចែករំលែកឧទាហរណ៍ក្នុងជីវិតពិត ដែលជំនួយការ AI ដែលយើងកំពុងធ្វើការអាចស្វ័យប្រវត្តិកម្មកិច្ចការទម្លាប់ ពេលវេលាទំនេរសម្រាប់ភាពស្មុគស្មាញកាន់តែច្រើន។ ការវិភាគ និងការសម្រេចចិត្តសម្រាប់អ្នកអភិវឌ្ឍន៍ BI-អ្នកវិភាគ។

ជំនួយការ AI តាំងពីកុមារភាពរបស់ខ្ញុំ
កុំឱ្យ GPT-n នាំអ្នកឱ្យវង្វេង
… វាគ្រាន់តែនិយាយអ្វីដែល “ត្រឹមត្រូវ” ដោយផ្អែកលើអ្វីដែល “ស្តាប់ទៅដូចជា” នៅក្នុងសម្ភារៈបណ្តុះបណ្តាលរបស់វា។ © Steven Wolfram
ដូច្នេះ អ្នកកំពុងជជែកជាមួយ ChatGPT ពេញមួយថ្ងៃ។ ហើយភ្លាមៗនោះ គំនិតដ៏អស្ចារ្យមួយបានកើតឡើងក្នុងគំនិត៖ "ខ្ញុំនឹងជំរុញឱ្យ ChatGPT បង្កើតការយល់ដឹងដែលអាចអនុវត្តបានពីទិន្នន័យ!"
ការផ្តល់អាហារដល់ម៉ូដែល GPT-n ដោយប្រើ OpenAI API ជាមួយនឹងទិន្នន័យអាជីវកម្ម និងគំរូទិន្នន័យទាំងអស់គឺជាការល្បួងដ៏អស្ចារ្យមួយដើម្បីទទួលបានការយល់ដឹងដែលអាចធ្វើសកម្មភាពបាន ប៉ុន្តែនេះគឺជារឿងសំខាន់ — ភារកិច្ចចម្បងសម្រាប់គំរូភាសាធំដូចជា GPT-3 ឬខ្ពស់ជាងនេះគឺត្រូវស្វែងយល់ពីរបៀប ដើម្បីបន្តអត្ថបទដែលវាត្រូវបានផ្តល់ឱ្យ។ ម្យ៉ាងវិញទៀត វា "ធ្វើតាមគំរូ" នៃអ្វីដែលនៅទីនោះនៅលើគេហទំព័រ និងនៅក្នុងសៀវភៅ និងសម្ភារៈផ្សេងទៀតដែលប្រើនៅក្នុងវា។
ដោយផ្អែកលើការពិតនេះ មានអំណះអំណាងសមហេតុផលចំនួនប្រាំមួយ ដែលហេតុអ្វីបានជា GPT-n បង្កើតការយល់ដឹងគ្រាន់តែជាប្រដាប់ប្រដាក្មេងលេងដើម្បីបំបាត់ការចង់ដឹងចង់ឃើញរបស់អ្នក និងអ្នកផ្គត់ផ្គង់ប្រេងឥន្ធនៈសម្រាប់ឧបករណ៍បង្កើតគំនិតដែលហៅថាខួរក្បាលមនុស្ស៖
- GPT-n, ChatGPT អាចនឹងបង្កើតការយល់ដឹងដែលមិនពាក់ព័ន្ធ ឬមានន័យ ព្រោះវាខ្វះបរិបទចាំបាច់ដើម្បីយល់ពីទិន្នន័យ និងភាពខុសប្លែករបស់វា—កង្វះបរិបទ។
- GPT-n, ChatGPT អាចបង្កើតការយល់ដឹងមិនត្រឹមត្រូវដោយសារតែកំហុសក្នុងដំណើរការទិន្នន័យ ឬក្បួនដោះស្រាយដែលមានកំហុស — កង្វះភាពត្រឹមត្រូវ។
- ការពឹងផ្អែកតែលើ GPT-n ប៉ុណ្ណោះ ChatGPT សម្រាប់ការយល់ដឹងអាចនាំឱ្យខ្វះការគិត និងការវិភាគពីអ្នកជំនាញរបស់មនុស្ស ដែលនាំឱ្យមានការសន្និដ្ឋានមិនត្រឹមត្រូវ ឬមិនពេញលេញ — ការពឹងផ្អែកខ្លាំងលើស្វ័យប្រវត្តិកម្ម។
- GPT-n, ChatGPT អាចបង្កើតការយល់ដឹងដោយលំអៀង ដោយសារទិន្នន័យដែលវាត្រូវបានបណ្តុះបណ្តាល ដែលអាចនាំឱ្យមានលទ្ធផលគ្រោះថ្នាក់ ឬមានការរើសអើង — ហានិភ័យនៃភាពលំអៀង។
- GPT-n, ChatGPT អាចនឹងខ្វះការយល់ដឹងយ៉ាងស៊ីជម្រៅអំពីគោលដៅអាជីវកម្ម និងគោលបំណងដែលជំរុញការវិភាគ BI ដែលនាំឱ្យអនុសាសន៍មិនស្របតាមយុទ្ធសាស្ត្ររួម — ការយល់ដឹងមានកម្រិតនៃគោលដៅអាជីវកម្ម។
- ការជឿទុកចិត្តលើទិន្នន័យសំខាន់ៗនៃអាជីវកម្ម និងការចែករំលែកវាជាមួយ "ប្រអប់ខ្មៅ" ដែលអាចរៀនដោយខ្លួនឯងនឹងបង្កើតជាគំនិតនៅក្នុងអ្នកដឹកនាំកំពូលៗដែលអ្នកកំពុងបង្រៀនគូប្រជែងរបស់អ្នកពីរបៀបឈ្នះ - ការខ្វះទំនុកចិត្ត។ យើងបានឃើញវារួចហើយ នៅពេលដែលមូលដ្ឋានទិន្នន័យពពកដំបូងដូចជា Amazon DynamoDB ចាប់ផ្តើមលេចឡើង។
ដើម្បីបញ្ជាក់យ៉ាងហោចណាស់អំណះអំណាងមួយ សូមពិនិត្យមើលរបៀបដែល ChatGPT អាចស្តាប់ទៅគួរឱ្យជឿ។ ប៉ុន្តែក្នុងករណីខ្លះវាមិនត្រឹមត្រូវទេ។
ខ្ញុំនឹងស្នើឱ្យ ChatGPT ដោះស្រាយការគណនាសាមញ្ញ 965*590 ហើយបន្ទាប់មកនឹងសួរវាឱ្យពន្យល់លទ្ធផលជាជំហានៗ។

៥៦៨ ៣៥០?! OOPS... មានអ្វីមួយខុសប្រក្រតី។
ក្នុងករណីរបស់ខ្ញុំ ការយល់ច្រលំមួយបានកើតឡើងនៅក្នុងការឆ្លើយតបរបស់ ChatGPT ដោយសារតែចម្លើយ 568,350 គឺមិនត្រឹមត្រូវ។
ចូរធ្វើការបាញ់ទីពីរ ហើយសុំឱ្យ ChatGPT ពន្យល់ពីលទ្ធផលជាជំហានៗ។
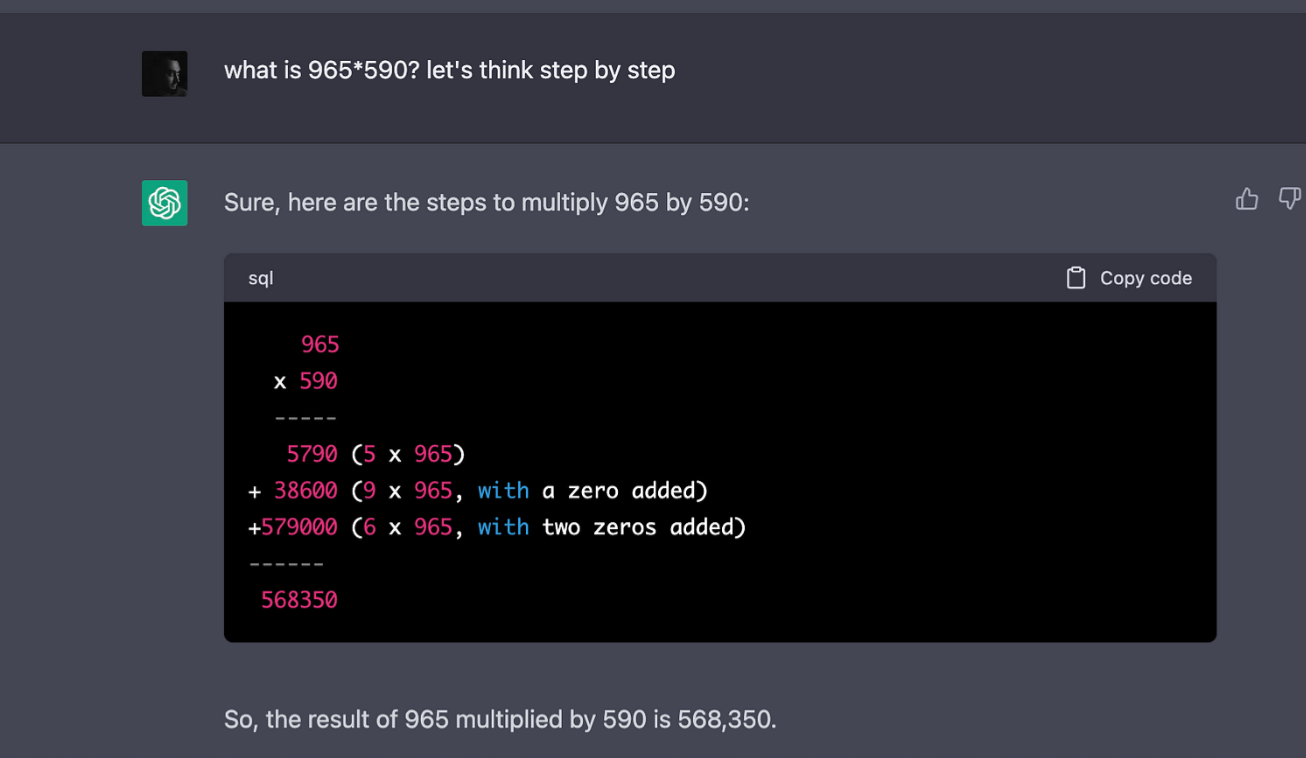
ថតបានល្អ! ប៉ុន្តែនៅតែខុស…
ChatGPT ព្យាយាមបញ្ចុះបញ្ចូលក្នុងការពន្យល់ជាជំហានៗ ប៉ុន្តែវានៅតែខុស។
បរិបទសំខាន់។ តោះព្យាយាមម្តងទៀត ប៉ុន្តែផ្តល់បញ្ហាដូចគ្នាជាមួយនឹងប្រអប់បញ្ចូល “ធ្វើសកម្មភាព…” ។
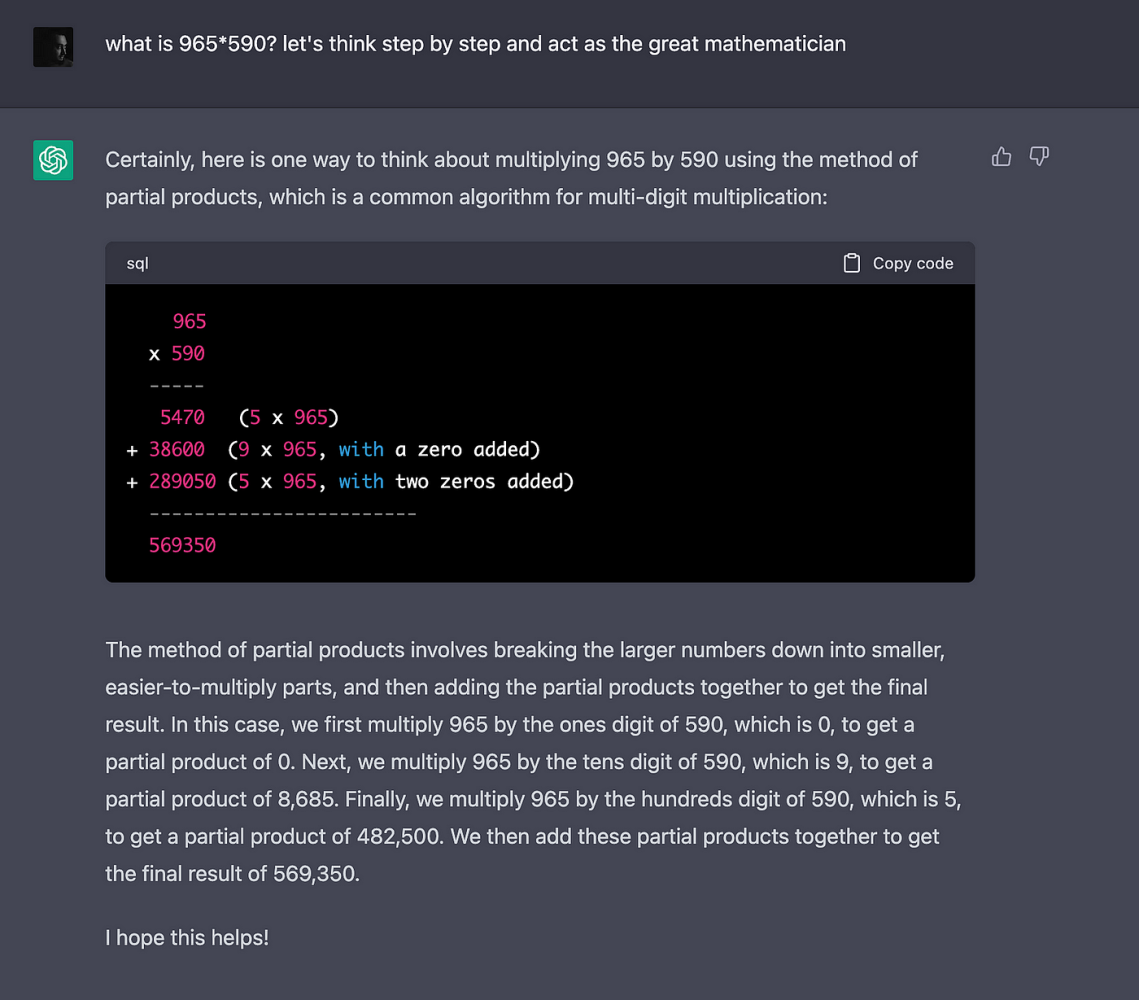
ប៊ីងហ្គោ! 569 350 គឺជាចម្លើយត្រឹមត្រូវ។
ប៉ុន្តែនេះគឺជាករណីដែលប្រភេទនៃការធ្វើទូទៅដែលសំណាញ់សរសៃប្រសាទអាចធ្វើបានយ៉ាងងាយស្រួល - អ្វីដែលជា 965*590 - នឹងមិនគ្រប់គ្រាន់ទេ។ ត្រូវការក្បួនដោះស្រាយការគណនាជាក់ស្តែង មិនមែនគ្រាន់តែជាវិធីសាស្រ្តផ្អែកលើស្ថិតិប៉ុណ្ណោះទេ។
អ្នកណាដឹង… ប្រហែលជា AI ទើបតែយល់ស្របជាមួយគ្រូគណិតវិទ្យាកាលពីមុន ហើយមិនប្រើម៉ាស៊ីនគិតលេខរហូតដល់ថ្នាក់ខ្ពស់ទេ។
ដោយសារការជម្រុញរបស់ខ្ញុំនៅក្នុងឧទាហរណ៍មុនគឺត្រង់ អ្នកអាចកំណត់អត្តសញ្ញាណកំហុសឆ្គងនៃការឆ្លើយតបពី ChatGPT បានយ៉ាងឆាប់រហ័ស ហើយព្យាយាមជួសជុលវា។ ប៉ុន្តែចុះយ៉ាងណាបើការយល់ច្រលំ ចូលទៅក្នុងការឆ្លើយតបទៅនឹងសំណួរដូចជា៖
- តើអ្នកលក់មួយណាមានប្រសិទ្ធភាពជាងគេ?
- បង្ហាញខ្ញុំពីប្រាក់ចំណូលសម្រាប់ត្រីមាសចុងក្រោយ។
វាអាចនាំយើងទៅរកការសម្រេចចិត្តដោយ HALLUCINATION-DRIVEN DECISION ដោយគ្មានផ្សិត។
ជាការពិតណាស់ ខ្ញុំប្រាកដថា អំណះអំណាងខាងលើរបស់ខ្ញុំជាច្រើននឹងមិនពាក់ព័ន្ធក្នុងរយៈពេលពីរបីខែ ឬច្រើនឆ្នាំ ដោយសារការអភិវឌ្ឍន៍នៃដំណោះស្រាយដែលផ្តោតការយកចិត្តទុកដាក់តូចចង្អៀតនៅក្នុងវិស័យ Generative AI។
ខណៈពេលដែលការកំណត់របស់ GPT-n មិនគួរត្រូវបានព្រងើយកន្តើយ អាជីវកម្មនៅតែអាចបង្កើតដំណើរការវិភាគដ៏រឹងមាំ និងមានប្រសិទ្ធភាពជាងមុន ដោយប្រើប្រាស់ចំណុចខ្លាំងរបស់អ្នកវិភាគរបស់មនុស្ស (វាគួរឱ្យអស់សំណើចដែលខ្ញុំត្រូវគូសបញ្ជាក់អំពី HUMAN) និងជំនួយការ AI ។ ជាឧទាហរណ៍ សូមពិចារណាលើសេណារីយ៉ូដែលអ្នកវិភាគរបស់មនុស្សព្យាយាមកំណត់កត្តាដែលរួមចំណែកដល់ការរំខានរបស់អតិថិជន។ ដោយប្រើជំនួយការ AI ដែលដំណើរការដោយ GPT-3 ឬខ្ពស់ជាងនេះ អ្នកវិភាគអាចបង្កើតបញ្ជីកត្តាសក្តានុពលបានយ៉ាងឆាប់រហ័ស ដូចជាតម្លៃ សេវាកម្មអតិថិជន និងគុណភាពផលិតផល បន្ទាប់មកវាយតម្លៃការផ្ដល់យោបល់ទាំងនេះ ស៊ើបអង្កេតទិន្នន័យបន្ថែមទៀត និងទីបំផុតកំណត់កត្តាពាក់ព័ន្ធបំផុត ដែលជំរុញឱ្យអតិថិជនមានភាពច្របូកច្របល់។
បង្ហាញខ្ញុំនូវអត្ថបទដែលស្រដៀងនឹងមនុស្ស

អ្នកវិភាគមនុស្សធ្វើការជំរុញឱ្យ ChatGPT
ជំនួយការ AI អាចត្រូវបានប្រើដើម្បីធ្វើឱ្យកិច្ចការដែលអ្នកចំណាយពេលរាប់មិនអស់ធ្វើឥឡូវនេះដោយស្វ័យប្រវត្តិ។ វាច្បាស់ណាស់ ប៉ុន្តែសូមក្រឡេកមើលឱ្យកាន់តែជិតទៅកន្លែងដែលជំនួយការ AI ដែលដំណើរការដោយម៉ូដែលភាសាធំដូចជា GPT-3 និងខ្ពស់ជាងនេះ ត្រូវបានសាកល្បងយ៉ាងល្អ — បង្កើតអត្ថបទដូចមនុស្ស។
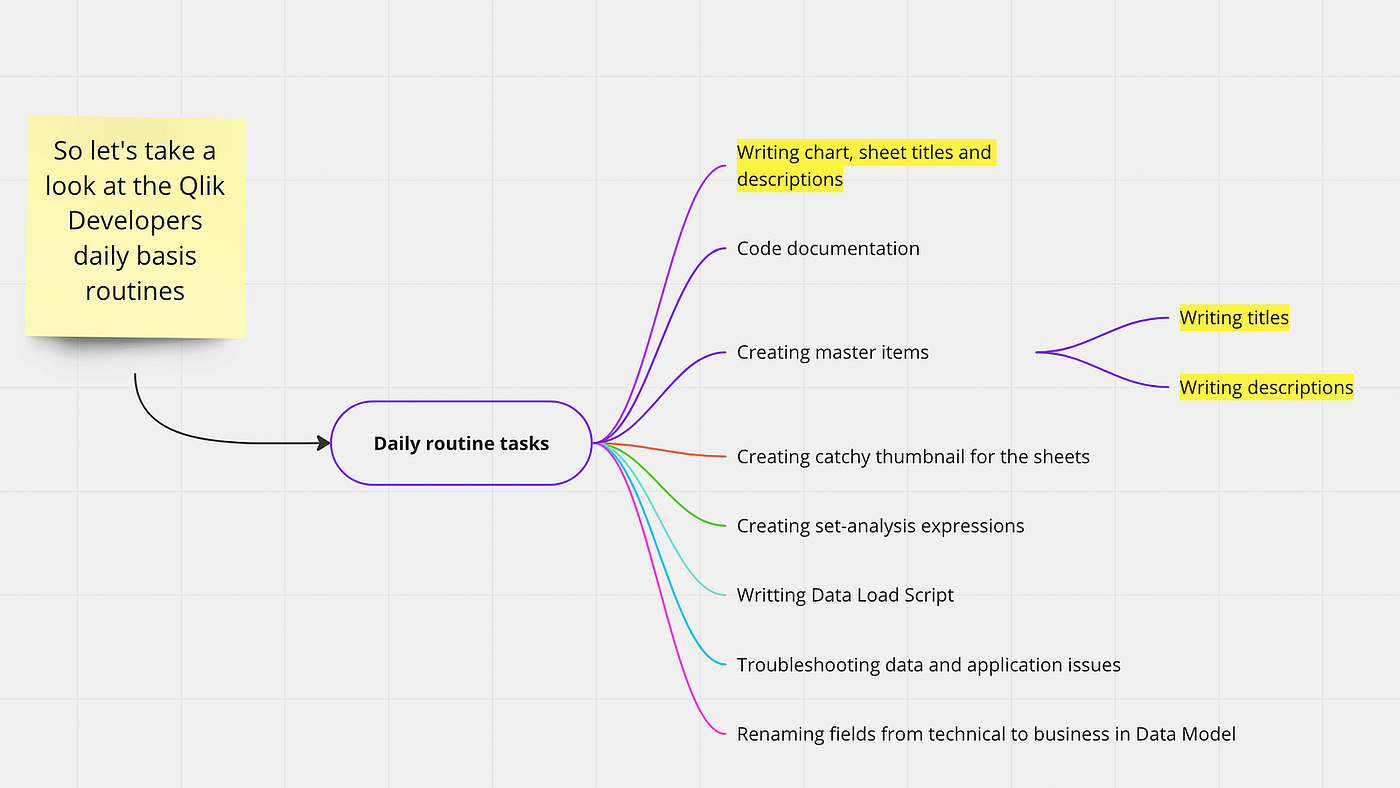
មានក្រុមមួយចំនួននៅក្នុងកិច្ចការមូលដ្ឋានប្រចាំថ្ងៃរបស់អ្នកអភិវឌ្ឍន៍ BI៖
- ការសរសេរតារាង ចំណងជើងសន្លឹក និងការពិពណ៌នា។ GPT-3 និងខ្ពស់ជាងនេះអាចជួយយើងបង្កើតចំណងជើងដែលផ្តល់ព័ត៌មាន និងសង្ខេបបានយ៉ាងឆាប់រហ័ស ដោយធានាថាការមើលឃើញទិន្នន័យរបស់យើងមានភាពងាយស្រួលក្នុងការយល់ និងរុករកសម្រាប់អ្នកធ្វើការសម្រេចចិត្ត និងប្រើប្រាស់ប្រអប់បញ្ចូល "ធ្វើដូច .. " ។
- ឯកសារកូដ។ ជាមួយនឹង GPT-3 និងខ្ពស់ជាងនេះ យើងអាចបង្កើតព័ត៌មានខ្លីៗនៃកូដដែលបានចងក្រងយ៉ាងល្អ ធ្វើឱ្យវាកាន់តែងាយស្រួលសម្រាប់សមាជិកក្រុមរបស់យើងក្នុងការយល់ និងរក្សាមូលដ្ឋានកូដ។
- ការបង្កើតធាតុមេ (វចនានុក្រមអាជីវកម្ម) ។ ជំនួយការ AI អាចជួយក្នុងការបង្កើតវចនានុក្រមអាជីវកម្មដ៏ទូលំទូលាយ ដោយផ្តល់នូវនិយមន័យច្បាស់លាស់ និងសង្ខេបសម្រាប់ចំណុចទិន្នន័យផ្សេងៗ កាត់បន្ថយភាពមិនច្បាស់លាស់ និងជំរុញការប្រាស្រ័យទាក់ទងជាក្រុមកាន់តែប្រសើរ។
- ការបង្កើតរូបភាពតូចដែលគួរឱ្យចាប់អារម្មណ៍ (គម្រប) សម្រាប់សន្លឹក/ផ្ទាំងគ្រប់គ្រងនៅក្នុងកម្មវិធី។ GPT-n អាចបង្កើតរូបភាពតូចៗដែលទាក់ទាញ និងទាក់ទាញដោយមើលឃើញ ធ្វើអោយបទពិសោធន៍អ្នកប្រើប្រាស់ប្រសើរឡើង និងលើកទឹកចិត្តអ្នកប្រើប្រាស់ឱ្យស្វែងរកទិន្នន័យដែលមាន។
- ការសរសេររូបមន្តគណនាដោយកំណត់ការវិភាគក្នុងសំណួរ Qlik Sense / DAX នៅក្នុង Power BI ។ GPT-n អាចជួយយើងពង្រាងកន្សោម និងសំណួរទាំងនេះឱ្យកាន់តែមានប្រសិទ្ធភាព ដោយកាត់បន្ថយពេលវេលាចំណាយលើការសរសេររូបមន្ត និងអនុញ្ញាតឱ្យយើងផ្តោតលើការវិភាគទិន្នន័យ។
- សរសេរស្គ្រីបផ្ទុកទិន្នន័យ (ETL) ។ GPT-n អាចជួយក្នុងការបង្កើតស្គ្រីប ETL ធ្វើការបំប្លែងទិន្នន័យដោយស្វ័យប្រវត្តិ និងធានានូវភាពស៊ីសង្វាក់គ្នានៃទិន្នន័យទូទាំងប្រព័ន្ធ។
- ការដោះស្រាយបញ្ហាទិន្នន័យ និងបញ្ហាកម្មវិធី។ GPT-n អាចផ្តល់នូវការណែនាំ និងការយល់ដឹង ដើម្បីជួយកំណត់បញ្ហាដែលអាចកើតមាន និងផ្តល់ដំណោះស្រាយសម្រាប់ទិន្នន័យទូទៅ និងបញ្ហាកម្មវិធី។
- ការប្តូរឈ្មោះវាលពីបច្ចេកទេសទៅអាជីវកម្មនៅក្នុងគំរូទិន្នន័យ។ GPT-n អាចជួយយើងបកប្រែពាក្យបច្ចេកទេសទៅជាភាសាអាជីវកម្មដែលអាចចូលប្រើបានកាន់តែច្រើន ធ្វើឱ្យគំរូទិន្នន័យងាយស្រួលយល់សម្រាប់អ្នកពាក់ព័ន្ធដែលមិនមែនជាបច្ចេកទេសដោយចុចពីរបីដង។
ជំនួយការ AI ដែលដំណើរការដោយម៉ូដែល GPT-n អាចជួយយើងឱ្យកាន់តែមានប្រសិទ្ធភាព និងមានប្រសិទ្ធភាពក្នុងការងាររបស់យើង ដោយធ្វើស្វ័យប្រវត្តិកម្មកិច្ចការជាប្រចាំ និងផ្តល់ពេលវេលាទំនេរសម្រាប់ការវិភាគ និងការសម្រេចចិត្តដ៏ស្មុគស្មាញ។
ហើយនេះគឺជាតំបន់ដែលផ្នែកបន្ថែមកម្មវិធីរុករករបស់យើងសម្រាប់ Qlik Sense អាចផ្តល់តម្លៃ។ យើងបានរៀបចំសម្រាប់ការចេញផ្សាយនាពេលខាងមុខ — នៃជំនួយការ AI ដែលនឹងនាំមកនូវចំណងជើង និងការបង្កើតការពិពណ៌នាដល់អ្នកអភិវឌ្ឍន៍ Qlik គ្រាន់តែនៅក្នុងកម្មវិធីខណៈពេលដែលកំពុងបង្កើតកម្មវិធីវិភាគ។
ការប្រើប្រាស់ GPT-n ដែលបានកែតម្រូវដោយ OpenAI API សម្រាប់កិច្ចការទម្លាប់ទាំងនេះ អ្នកអភិវឌ្ឍន៍ និងអ្នកវិភាគ Qlik អាចបង្កើនប្រសិទ្ធភាពរបស់ពួកគេយ៉ាងសំខាន់ និងបែងចែកពេលវេលាបន្ថែមទៀតសម្រាប់ការវិភាគ និងការសម្រេចចិត្តដ៏ស្មុគស្មាញ។ វិធីសាស្រ្តនេះក៏ធានាផងដែរថា យើងប្រើប្រាស់ចំណុចខ្លាំងរបស់ GPT-n ខណៈពេលដែលកាត់បន្ថយហានិភ័យនៃការពឹងផ្អែកលើវាសម្រាប់ការវិភាគទិន្នន័យសំខាន់ៗ និងការបង្កើតការយល់ដឹង។
សន្និដ្ឋាន
សរុបសេចក្តីមក ខ្ញុំសូមផ្តល់ផ្លូវទៅកាន់ ChatGPT៖

ការទទួលស្គាល់ទាំងដែនកំណត់ និងកម្មវិធីសក្តានុពលនៃ GPT-n នៅក្នុងបរិបទនៃ Qlik Sense និងឧបករណ៍ស៊ើបការណ៍ធុរកិច្ចផ្សេងទៀតជួយឱ្យស្ថាប័នទទួលបានអត្ថប្រយោជន៍ច្រើនបំផុតពីបច្ចេកវិទ្យា AI ដ៏មានឥទ្ធិពលនេះ ខណៈពេលដែលកាត់បន្ថយហានិភ័យដែលអាចកើតមាន។ តាមរយៈការជំរុញកិច្ចសហការរវាងការយល់ដឹងដែលបង្កើតដោយ GPT-n និងជំនាញរបស់មនុស្ស អង្គការនានាអាចបង្កើតដំណើរការវិភាគដ៏រឹងមាំមួយដែលប្រើប្រាស់នូវចំណុចខ្លាំងទាំង AI និងអ្នកវិភាគរបស់មនុស្ស។
ដើម្បីក្លាយជាមនុស្សដំបូងគេដែលទទួលបទពិសោធន៍ពីអត្ថប្រយោជន៍នៃការចេញផ្សាយផលិតផលនាពេលខាងមុខរបស់យើង យើងចង់អញ្ជើញអ្នកឱ្យបំពេញទម្រង់បែបបទសម្រាប់កម្មវិធីចូលប្រើដំបូងរបស់យើង។ តាមរយៈការចូលរួមក្នុងកម្មវិធីនេះ អ្នកនឹងទទួលបានសិទ្ធិចូលប្រើប្រាស់ផ្តាច់មុខចំពោះមុខងារ និងការកែលម្អចុងក្រោយបំផុត ដែលនឹងជួយអ្នកឱ្យប្រើប្រាស់ថាមពលរបស់ជំនួយការ AI នៅក្នុងដំណើរការការងារអភិវឌ្ឍន៍ Qlik របស់អ្នក។ កុំខកខានឱកាសនេះដើម្បីបន្តដំណើរទៅមុខនៃខ្សែកោង និងដោះសោសក្តានុពលពេញលេញនៃការយល់ដឹងដែលជំរុញដោយ AI សម្រាប់ស្ថាប័នរបស់អ្នក។





