KI: Pandora's Box of Innovation
Om 'n balans te vind tussen die oplossing van die nuwe vrae wat KI veroorsaak en die voordele van innovasie
Daar is twee groot kwessies wat verband hou met KI en intellektuele eiendom. Een daarvan is die gebruik van inhoud. Die gebruiker voer inhoud in in die vorm van 'n prompt waarop die KI een of ander aksie uitvoer. Wat gebeur met daardie inhoud nadat KI reageer? Die ander is KI se skepping van inhoud. KI gebruik sy algoritmes en kennisbasis van opleidingsdata om op 'n versoek te reageer en uitset te genereer. Met inagneming van die feit dat dit opgelei is oor potensieel kopieregmateriaal en ander intellektuele eiendom, is die uitsetroman genoeg vir kopiereg?
KI se gebruik van intellektuele eiendom
Dit lyk asof KI en ChatGPT elke dag in die nuus is. ChatGPT, of Generative Pre-trained Transformer, is 'n KI-kletsbot wat laat 2022 bekendgestel is deur OpenAI. ChatGPT gebruik 'n KI-model wat met die internet opgelei is. Die nie-winsgewende maatskappy, OpenAI, bied tans 'n gratis weergawe van ChatGPT aan wat hulle die navorsingsvoorskou. “Die OpenAI API kan toegepas word op feitlik enige taak wat die verstaan of generering van natuurlike taal, kode of beelde behels. “(Bron). Benewens die gebruik Klets GPT as 'n oop gesprek met en KI-assistent (of, Marv, 'n sarkastiese kletsbot wat onwillig vrae beantwoord), kan dit ook gebruik word om:
- Vertaal programmeertale - Vertaal van een programmeertaal na 'n ander.
- Verduidelik kode – Verduidelik 'n ingewikkelde stuk kode.
- Skryf 'n Python docstring - Skryf 'n docstring vir 'n Python funksie.
- Maak foute in Python-kode reg - Soek en maak foute in bronkode reg.
Die vinnige aanvaarding van KI
Sagtewaremaatskappye sukkel om KI in hul toepassings te integreer. Daar is 'n kothuisbedryf rondom ChatGPT. Sommige skep toepassings wat die API's daarvan gebruik. Daar is selfs een webwerf wat homself as 'n ChatGPT vinnige mark. Hulle verkoop ChatGPT-opdragte!

Samsung was een maatskappy wat die potensiaal raakgesien het en op die wa gespring het. 'n Ingenieur by Samsung het ChatGPT gebruik om hom te help om 'n kode te ontfout en hom te help om die foute reg te stel. Eintlik het ingenieurs by drie afsonderlike geleenthede korporatiewe IP in die vorm van bronkode na OpenAI opgelaai. Samsung het toegelaat – sommige bronne sê, aangemoedig – sy ingenieurs in die halfgeleierafdeling om ChatGPT te gebruik om vertroulike bronkode te optimaliseer en reg te stel. Nadat daardie spreekwoordelike perd uitgenooi is weiveld toe, het Samsung die skuurdeur toegeslaan deur inhoud wat met ChatGPT gedeel word tot minder as 'n twiet te beperk en die personeel wat by die datalek betrokke was, te ondersoek. Dit oorweeg dit nou om sy eie kletsbot te bou. (Beeld gegenereer deur ChatGPT – 'n potensieel onbedoelde ironiese, indien nie humoristiese, reaksie op die opdrag, 'n span Samsung sagteware-ingenieurs wat OpentAI ChatGPT gebruik om sagtewarekode te ontfout wanneer hulle met verbasing en afgryse besef dat die tandepasta uit die buis is en hulle het korporatiewe intellektuele eiendom aan die internet blootgestel”.)
Om die sekuriteitskending as 'n "lekkasie" te klassifiseer, kan 'n verkeerde benaming wees. As jy 'n kraan oopdraai, is dit nie 'n lek nie. Analoog moet enige inhoud wat jy in OpenAI invoer, as publiek beskou word. Dit is OOP AI. Dit word vir 'n rede oop genoem. Enige data wat jy in ChatGpt invoer, kan gebruik word "om hul KI-dienste te verbeter of kan deur hulle en/of selfs hul verwante vennote gebruik word vir 'n verskeidenheid doeleindes." (Bron.) OpenAI waarsku wel gebruikers in sy gebruiker lei: “Ons is nie in staat om spesifieke versoeke uit jou geskiedenis te skrap nie. Moet asseblief nie enige sensitiewe inligting in jou gesprekke deel nie,” ChatGPT sluit selfs 'n voorbehoud in reaksies, "Neem asseblief kennis dat die kletskoppelvlak bedoel is as 'n demonstrasie en nie bedoel is vir produksiegebruik nie."
Samsung is nie die enigste maatskappy wat eie, persoonlike en vertroulike inligting in die natuur vrystel nie. 'n Navorsing maatskappy gevind dat alles van korporatiewe strategiese dokumente tot pasiënt se name en mediese diagnose in ChatGPT gelaai is vir ontleding of verwerking. Daardie data word deur ChatGPT gebruik om die KI-enjin op te lei en om die vinnige algoritmes te verfyn.
Gebruikers weet meestal nie hoe hul sensitiewe persoonlike identifiserende inligting bestuur, gebruik, gestoor of selfs gedeel word nie. Aanlyn bedreigings en kwesbaarhede in KI-klets is beduidende sekuriteitskwessies as 'n organisasie en sy stelsels gekompromitteer word, die persoonlike data uitgelek, gesteel en vir kwaadwillige doeleindes gebruik word.
Die aard van KI-klets is om 'n groot hoeveelheid data, insluitend persoonlike inligting, te verwerk en te ontleed om relevante resultate te lewer. Dit blyk egter dat die gebruik van groot data afwyk van die konsep van privaatheid ...(Bron.)
Dit is nie 'n aanklag van KI nie. Dit is 'n herinnering. Dit is 'n herinnering dat KI soos die internet behandel moet word. Met ander woorde, beskou enige inligting wat jy in OpenAI invoer as publiek. (Onthou ook dat enige uitset wat deur KI gegenereer word verder getransformeer kan word of as 'n model gebruik kan word om antwoorde vir toekomstige gebruikers te genereer.) Dit is een manier waarop KI intellektuele eiendom en privaatheid in gedrang bring. Nog 'n kontroversie is KI se gebruik van materiaal met kopiereg.
KI en die kopiereg-dilemma
Daar is 'n aantal bekommernisse wat verband hou met KI billike gebruik en kopieregmateriaal. KI is in staat om die geskrewe woord te verwerk. Dit kan opsom, ontleed, kategoriseer en selfs nuwe inhoud skep gebaseer op 'n bepaalde skryfstyl. KI is opgelei op inhoud. Ek dink dit sal vir hom moeilik wees om die gebruik van kopieregmateriaal te vermy. Sover ek weet, spreek huidige wetgewing nie die gebruik van kopiereg-inhoud vir opleiding volledig aan nie. (Image)
Ek het OpenAI gevra om die teks vir die eerste bladsy van "To Kill a Mockingbird" deur Harper Lee te tik. Dit het. So, ek is redelik seker dat dit toegang het tot die teks met kopiereg. Dit kan dan 'n CV in die styl van Harper Lee skep. Of jy kan dit vra om 'n sonnet te skep gebaseer op die tema van die boek.
| 'n Shakespearese sonet
Gebaseer op die tema van "To Kill a Mockingbird" In Maycomb se dorp waar geregtigheid 'n droom lyk, Young Scout en Jem vind waarheid verby hul jare. Hul pa, Atticus, 'n edele tema Wie se morele kompas hulle deur hul vrese lei. Tom Robinson, 'n swart man wat valslik beskuldig word, 'n Stem geweier, 'n verhoor wat regverdig en regverdig is. Maar Atticus verdedig hom, nie geamuseerd nie, Want waarheid en geregtigheid moet ons saak wees. Die spotvoël, 'n simbool van pure genade, Onskuldig aan skade bring sy lied vrede. Maar boosheid skuil in hierdie klein dorpie se ruimte, En geregtigheid val as haat begin toeneem. Harper Lee se woorde, 'n waarskuwing aan ons almal, Om te veg vir geregtigheid, sodat dit nie ons val is nie. |
|---|
Daar is geen kans dat dit met Shakespeare se werk – of Harper Lee s’n vir die saak – verkeerd sal wees nie. Dit is transformerende nuwe inhoud wat duidelik nie met die oorspronklike verwar moet word nie. Verskeie vrae ontstaan. Op watter stadium word dit transformasioneel? Met ander woorde, hoeveel moet die oorspronklike werk verander word om as nuwe inhoud beskou te word?
Nog 'n vraag - en dit geld net so vir enige inhoud wat deur KI geskep word - wie besit dit? Wie besit die kopiereg op die inhoud? Of kan die werk selfs kopiereg beskerm word? 'n Argument kan gemaak word dat die eienaar van die kopiereg die individu moet wees wat die versoek gemaak het en die versoek van OpenAI gemaak het. Daar is 'n nuwe kothuisbedryf rondom vinnige outeurs. Op sommige aanlynmarkplekke kan jy tussen $2 en 20 betaal vir opdragte wat jou rekenaargegenereerde kuns of geskrewe teks sal gee.
Ander sê dit behoort aan die ontwikkelaar van OpenAI te behoort. Dit laat nog meer vrae ontstaan. Hang dit af van die model of enjin wat gebruik word om die reaksie te genereer?
Ek dink die mees oortuigende argument wat gemaak moet word, is dat inhoud wat deur 'n rekenaar gegenereer word nie kopiereg beskerm kan word nie. Die Amerikaanse kopieregkantoor het 'n beleidsverklaring uitgereik in die Federale Register, Maart 2023. Daarin sê dit, "Omdat die Kantoor elke jaar ongeveer 'n halfmiljoen aansoeke vir registrasie ontvang, sien dit nuwe neigings in registrasie-aktiwiteit wat moontlik vereis dat die inligting wat op 'n aansoek bekend gemaak moet word, gewysig of uitgebrei moet word." Dit gaan voort om te sê: "Hierdie tegnologieë, wat dikwels as 'generatiewe KI' beskryf word, laat vrae ontstaan oor die vraag of die materiaal wat hulle vervaardig deur kopiereg beskerm word, of werke wat bestaan uit beide mens-outeur en KI-gegenereerde materiaal geregistreer mag word, en wat inligting moet aan die Kantoor verskaf word deur aansoekers wat hulle wil registreer.”
“Die Kantoor” erken dat daar vrae is wat verband hou met die toepassing van 'n 150 jaar oue wet op tegnologie wat nog nie sy eerste verjaardag gesien het nie. Om hierdie vrae aan te spreek, het die Kopieregkantoor 'n inisiatief geloods om die kwessie te bestudeer. Dit gaan navorsing doen en oopmaak vir publieke kommentaar oor hoe dit die gebruik van kopiereg-inhoud in die opleiding van KI moet aanspreek, asook hoe dit die inhoud wat gegenereer moet oorweeg.
Die Federale Register, ietwat verrassend, bied kleurkommentaar en beskryf 'n aantal interessante gevalle wat verband hou met die "outeurskap" van werke en sy historiese beleid oor kopiereg. Een saak wat bereg is, het bepaal dat 'n aap nie 'n kopiereg kan hê nie. In hierdie spesifieke geval het ape beelde met 'n kamera vasgelê. Die hof het beslis dat die beelde nie kopiereg kan kry nie omdat die Outeursregwet verwys na 'n skrywer se ''kinders'' ''weduwee'' ''kleinkinders'' en ''wewenaar'. In die hof se oë het hierdie taal ape uitgesluit. "Die Kantoor se bestaande registrasieriglyne het lank vereis dat werke die produk van menslike outeurskap moet wees."
Wanneer OpenAI oor die omstredenheid gevra word, sê dit: “Ja, daar is grys areas van intellektuele eiendomsreg wanneer dit by sagteware en KI kom. As gevolg van die kompleksiteit van die tegnologie en die gebrek aan gevestigde wetlike presedente, is dit dikwels moeilik om te bepaal watter regte 'n skepper op hul werk het. As 'n KI-algoritme byvoorbeeld op 'n roman of 'n bestaande sagtewareprogram gebaseer is, is dit nie altyd duidelik wie die regte op die algoritme of die oorspronklike werk besit nie. Boonop is die omvang van patentbeskerming vir KI-verwante uitvindings ’n omstrede regskwessie.”
OpenAI is reg hieroor. Dit is duidelik dat 'n Amerikaanse aansoek om kopiereg menslike outeurskap moet hê. Tussen nou en die einde van die jaar sal die Kopieregkantoor poog om van die oorblywende vrae uit te sorteer en bykomende leiding te verskaf.
Patentereg en KI
Besprekings oor Amerikaanse patentwetgewing en of dit uitvindings dek wat deur KI gemaak is, is 'n soortgelyke storie. Tans, soos die wet geskryf is, moet patenteerbare uitvindings deur natuurlike persone gemaak word. Die Amerikaanse Hooggeregshof het geweier om 'n saak aan te hoor wat daardie idee betwis. (Bron.) Soos die Amerikaanse kopieregkantoor, evalueer die Amerikaanse patent- en handelsmerkkantoor sy posisie. Dit is moontlik dat die USPTO besluit om intellektuele eiendomsbesit meer kompleks te maak. Die KI-skeppers, ontwikkelaars, eienaars besit dalk 'n deel van die uitvinding wat dit help om te skep. Kan 'n nie-mens deel-eienaar wees?
Die tegnologie-reus Google het onlangs ingeweeg. "'Ons glo dat KI nie as 'n uitvinder onder die Amerikaanse patentwet bestempel moet word nie, en glo dat mense patente moet hou op innovasies wat met behulp van KI tot stand gebring is," het Laura Sheridan, senior patentraadgewer by Google, gesê. In Google se verklaring beveel dit verhoogde opleiding en bewustheid van KI, die gereedskap, die risiko's en beste praktyke vir patenteksaminatore aan. (Bron.) Waarom aanvaar die Patentkantoor nie die gebruik van KI om KI te evalueer nie?
AI en die toekoms
Die vermoëns van KI en, in werklikheid, die hele KI-landskap het in net die afgelope 12 maande verander, of so. Baie maatskappye wil die krag van KI benut en die voorgestelde voordele van vinniger en goedkoper kode en inhoud pluk. Beide besigheid en die wet moet 'n beter begrip hê van die implikasies van die tegnologie aangesien dit verband hou met privaatheid, intellektuele eiendom, patente en kopiereg. (Beeld gegenereer deur ChatGPT met menslike prompt "KI en die toekoms". Let wel, beeld is nie kopieregbeskermd nie).
Opdatering: 17 Mei 2023
Daar is steeds elke dag ontwikkelings wat verband hou met KI en die wet. Die Senaat het 'n Regterlike Subkomitee oor Privaatheid, Tegnologie en die Reg. Dit hou 'n reeks verhore oor Toesig oor KI: Reël vir Kunsmatige Intelligensie. Dit beoog "om die reëls van KI te skryf." Met die doel "om daardie nuwe tegnologieë te ontmystifiseer en aanspreeklik te hou om sommige van die foute van die verlede te vermy," sê voorsitter van die subkomitee, Sen. Richard Blumenthal. Interessant genoeg, om die vergadering te open, het hy 'n diep vals klank gespeel en sy stem gekloon met ChatGPT-inhoud wat opgelei is op sy vorige opmerkings:
Te dikwels het ons gesien wat gebeur wanneer tegnologie regulering oorskry. Die ongebreidelde uitbuiting van persoonlike data, die verspreiding van disinformasie en die verdieping van maatskaplike ongelykhede. Ons het gesien hoe algoritmiese vooroordele diskriminasie en vooroordeel kan voortduur en hoe die gebrek aan deursigtigheid openbare vertroue kan ondermyn. Dit is nie die toekoms wat ons wil hê nie.
Dit oorweeg 'n aanbeveling om 'n nuwe Regulerende Agentskap vir Kunsmatige Intelligensie te skep wat gebaseer is op die modelle van die Food and Drug Administration (FDA) en die Nuclear Regulatory Commission (NRC). (Bron.) Een van die getuies voor die KI-subkomitee het voorgestel dat KI op soortgelyke wyse gelisensieer moet word as hoe farmaseutiese produkte deur die FDA gereguleer word. Ander getuies beskryf die huidige stand van KI as die Wilde Weste met gevare van vooroordeel, min privaatheid en sekuriteitskwessies. Hulle beskryf 'n Wes-wêreld-distopie van masjiene wat "kragtig, roekeloos en moeilik is om te beheer."
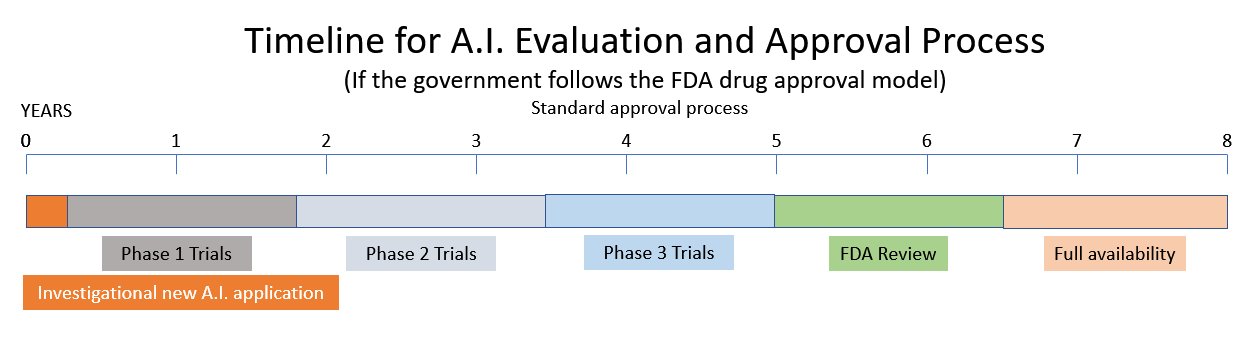
Om 'n nuwe middel op die mark te bring, neem 10 – 15 jaar en 'n halfmiljard dollar. (Bron.) Dus, as die Regering besluit om die modelle van die NRC en FDA te volg, kyk vir die onlangse tsoenami van opwindende innovasie op die gebied van Kunsmatige Intelligensie wat in die baie nabye toekoms deur regeringsregulering en rompslomp vervang sal word.






.jpg){kind=link}