AI: Pandoras æske eller innovation
At finde en balance mellem at løse de nye spørgsmål AI rejser og fordelene ved innovation
Der er to store problemer relateret til kunstig intelligens og intellektuel ejendomsret. Den ene er dens brug af indhold. Brugeren indtaster indhold i form af en prompt, hvorpå AI'en udfører en handling. Hvad sker der med det indhold, efter AI reagerer? Den anden er AI's skabelse af indhold. AI bruger sine algoritmer og videnbase af træningsdata til at reagere på en prompt og generere output. I betragtning af det faktum, at den er blevet trænet i potentielt ophavsretligt beskyttet materiale og anden intellektuel ejendomsret, er outputromanen nok til copyright?
AI's brug af intellektuel ejendom
Det ser ud til, at AI og ChatGPT er i nyhederne hver dag. ChatGPT, eller Generative Pre-trained Transformer, er en AI chatbot lanceret sent i 2022 af OpenAI. ChatGPT bruger en AI-model, der er blevet trænet ved hjælp af internettet. Den non-profit virksomhed, OpenAI, tilbyder i øjeblikket en gratis version af ChatGPT, som de kalder forhåndsvisning af forskning. "OpenAI API kan anvendes på stort set enhver opgave, der involverer forståelse eller generering af naturligt sprog, kode eller billeder. "(Kilde). Ud over at bruge ChatGPT som en åben samtale med en AI-assistent (eller, Marv, en sarkastisk chatbot, der modvilligt besvarer spørgsmål), kan den også bruges til at:
- Oversæt programmeringssprog – Oversæt fra et programmeringssprog til et andet.
- Forklar kode – Forklar et kompliceret stykke kode.
- Skriv en Python docstring – Skriv en docstring til en Python funktion.
- Ret fejl i Python-kode – Find og ret fejl i kildekoden.
Den hurtige indførelse af AI
Softwarevirksomheder kæmper for at integrere kunstig intelligens i deres applikationer. Der er en sommerhusindustri omkring ChatGPT. Nogle skaber applikationer, der udnytter deres API'er. Der er endda én hjemmeside, der fakturerer sig selv som en ChatGPT prompt markedsplads. De sælger ChatGPT-prompter!

Samsung var en virksomhed, der så potentialet og hoppede med på vognen. En ingeniør hos Samsung brugte ChatGPT til at hjælpe ham med at debugge noget kode og hjælpe ham med at rette fejlene. Faktisk uploadede ingeniører ved tre forskellige lejligheder virksomhedens IP i form af kildekode til OpenAI. Samsung tillod – nogle kilder siger, opfordrede – sine ingeniører i halvlederdivisionen til at bruge ChatGPT til at optimere og rette fortrolig kildekode. Efter at den ordsprogede hest var inviteret ud på græs, smækkede Samsung stalddøren ved at begrænse indhold, der blev delt med ChatGPT, til mindre end et tweet og efterforske personalet, der var involveret i datalækken. Det overvejer nu at bygge sin egen chatbot. (Billede genereret af ChatGPT - et potentielt utilsigtet ironisk, hvis ikke humoristisk, svar på prompten, "et team af Samsung-softwareingeniører, der bruger OpentAI ChatGPT til at fejlsøge softwarekode, når de med overraskelse og rædsel indser, at tandpastaen er ude af tuben og de har eksponeret virksomhedernes intellektuelle ejendomsret til internettet”.)
At klassificere sikkerhedsbruddet som en "lækage" kan være en forkert betegnelse. Hvis du åbner en vandhane, er det ikke en lækage. Analogt bør alt indhold, du indtaster i OpenAI, betragtes som offentligt. Det er OPEN AI. Det kaldes åben af en grund. Alle data, du indtaster i ChatGpt, kan blive brugt "til at forbedre deres AI-tjenester eller kan blive brugt af dem og/eller endda deres allierede partnere til en række forskellige formål." (Kilde.) OpenAI advarer brugere i sin bruger vejlede: "Vi er ikke i stand til at slette specifikke prompter fra din historie. Del venligst ikke nogen følsomme oplysninger i dine samtaler,” ChatGPT inkluderer endda en advarsel reaktioner, "bemærk venligst, at chatgrænsefladen er tænkt som en demonstration og ikke er beregnet til produktionsbrug."
Samsung er ikke det eneste firma, der frigiver proprietære, personlige og fortrolige oplysninger i naturen. En undersøgelse selskab fandt ud af, at alt fra virksomhedens strategiske dokumenter til patientens navne og medicinske diagnose var blevet indlæst i ChatGPT til analyse eller behandling. Disse data bliver brugt af ChatGPT til at træne AI-motoren og til at forfine promptalgoritmerne.
Brugere ved for det meste ikke, hvordan deres følsomme personlige identifikationsoplysninger administreres, bruges, opbevares eller endda deles. Onlinetrusler og sårbarheder i AI-chat er væsentlige sikkerhedsproblemer, hvis en organisation og dens systemer kompromitteres, de personlige data lækkes, stjæles og bruges til ondsindede formål.
Arten af AI-chat er at behandle og analysere en stor mængde data, inklusive personlige oplysninger, for at producere relevante resultater. Brugen af big data ser dog ud til at afvige fra begrebet privatliv...(Kilde.)
Dette er ikke en anklage mod AI. Det er en påmindelse. Det er en påmindelse om, at AI skal behandles som internettet. Med andre ord, betragte enhver information, du indlæser i OpenAI, som offentlig. (Husk også, at ethvert output genereret af AI kan transformeres yderligere eller bruges som en model til at generere svar til fremtidige brugere.) Det er en måde, hvorpå AI kompromitterer intellektuel ejendom og privatliv. En anden kontrovers er AI's brug af ophavsretligt beskyttet materiale.
AI og copyright-dilemmaet
Der er en række bekymringer relateret til AI fair use og ophavsretligt beskyttet materiale. AI er i stand til at behandle det skrevne ord. Det kan opsummere, analysere, kategorisere og endda skabe nyt indhold baseret på en bestemt skrivestil. AI er trænet i indhold. Jeg tror, det ville være svært for det at undgå at forbruge ophavsretligt beskyttet materiale. Så vidt jeg ved, behandler gældende lovgivning ikke fuldt ud brugen af ophavsretligt beskyttet indhold til træning. (Billede)
Jeg bad OpenAI om at skrive teksten til den første side af "To Kill a Mockingbird" af Harper Lee. Det gjorde. Så jeg er ret sikker på, at den har adgang til den ophavsretligt beskyttede tekst. Det kan derefter oprette et CV i stil med Harper Lee. Eller du kan bede den om at oprette en sonet baseret på bogens tema.
| En Shakespeares sonet
Baseret på temaet "To Kill a Mockingbird" I Maycombs by, hvor retfærdighed virker som en drøm, Young Scout og Jem finder sandheden længere end deres år. Deres far, Atticus, et ædelt tema Hvis moralske kompas leder dem gennem deres frygt. Tom Robinson, en sort mand falsk anklaget, Nægtet en stemme, en retssag, der er retfærdig. Men Atticus forsvarer ham, ikke moret, For sandhed og retfærdighed skal være vores sag. Spotfuglen, et symbol på ren ynde, Uskyldig i skade bringer dens sang fred. Men ondskaben lurer i denne lille bys rum, Og retfærdigheden falder, når hadet begynder at stige. Harper Lees ord, en advarsel til os alle, At kæmpe for retfærdighed, så det ikke bliver vores fald. |
|---|
Der er ingen chance for, at dette vil blive forvekslet med Shakespeares arbejde – eller Harper Lees for den sags skyld. Det er transformerende nyt indhold, der tydeligvis ikke skal forveksles med originalen. Der opstår flere spørgsmål. På hvilket tidspunkt bliver det transformerende? Med andre ord, hvor meget skal det originale værk ændres for, for at det kan betragtes som nyt indhold?
Et andet spørgsmål – og det gælder i lige så høj grad alt indhold skabt af AI – hvem ejer det? Hvem ejer ophavsretten til indholdet? Eller kan værket overhovedet være ophavsretligt beskyttet? Et argument kan fremføres, at ejeren af ophavsretten burde være den person, der lavede prompten og fremsatte anmodningen fra OpenAI. Der er en ny sommerhusindustri omkring hurtig forfatterskab. På nogle online markedspladser kan du betale mellem $2 og 20 for prompter, der giver dig computergenereret kunst eller skrevet tekst.
Andre siger, at det burde tilhøre udvikleren af OpenAI. Det rejser endnu flere spørgsmål. Afhænger det af modellen eller motoren, der bruges til at generere svaret?
Jeg tror, at det mest overbevisende argument, der kan fremføres, er, at indhold genereret af en computer ikke kan være ophavsretligt beskyttet. US Copyright Office udsendte en politikerklæring i Føderale register, marts 2023. I det, hedder det: "Fordi kontoret modtager omkring en halv million ansøgninger om registrering hvert år, ser det nye tendenser i registreringsaktivitet, der kan kræve ændring eller udvidelse af de oplysninger, der kræves for at blive offentliggjort på en ansøgning." Det fortsætter med at sige: "Disse teknologier, ofte beskrevet som 'generativ AI', rejser spørgsmål om, hvorvidt det materiale, de producerer, er beskyttet af ophavsret, om værker, der består af både menneskeskabt og AI-genereret materiale, kan registreres, og hvad oplysninger skal gives til kontoret af ansøgere, der ønsker at registrere dem."
"The Office" anerkender, at der er spørgsmål relateret til at anvende en 150 år gammel lov på teknologi, der ikke har set sin første fødselsdag. For at løse disse spørgsmål lancerede Copyright Office et initiativ for at undersøge spørgsmålet. Det vil undersøge og åbent for offentlig kommentar om, hvordan det skal adressere brugen af ophavsretligt beskyttet indhold i træningen af AI, samt hvordan det bør overveje det indhold, der genereres.
føderalt register, noget overraskende giver nogle farvekommentarer og beskriver en række interessante sager relateret til "forfatterskabet" af værker og dets historiske politikker om ophavsret. En sag, der blev dømt, mente, at en abe ikke kan have en ophavsret. I dette særlige tilfælde tog aber billeder med et kamera. Retten afgjorde, at billederne ikke kunne være ophavsretligt beskyttet, fordi ophavsretsloven henviser til en forfatters ''børn'' ''enke'' ''børnebørn'' og ''enkemand'. I rettens øjne udelukkede dette sprog aber. "Kontorets eksisterende registreringsvejledning har længe krævet, at værker er et produkt af menneskeligt forfatterskab."
Når OpenAI bliver spurgt om kontroversen, siger den: "Ja, der er gråzoner inden for intellektuel ejendomsret, når det kommer til software og AI. På grund af teknologiens kompleksitet og manglen på etablerede juridiske præcedenser, er det ofte svært at afgøre, hvilke rettigheder en skaber har til deres arbejde. For eksempel, hvis en AI-algoritme er baseret på en roman eller et eksisterende softwareprogram, er det ikke altid klart, hvem der ejer rettighederne til algoritmen eller det originale værk. Derudover er omfanget af patentbeskyttelse for AI-relaterede opfindelser et omstridt juridisk spørgsmål."
OpenAI har ret i dette. Det er klart, at en amerikansk ansøgning om ophavsret skal have menneskelig forfatterskab. Mellem nu og slutningen af året vil Copyright Office forsøge at løse nogle af de resterende spørgsmål og give yderligere vejledning.
Patentret og AI
Diskussioner omkring amerikansk patentlovgivning og om den dækker opfindelser lavet af AI er en lignende historie. I øjeblikket, som loven er skrevet, skal patenterbare opfindelser være lavet af fysiske personer. Den amerikanske højesteret nægtede at behandle en sag, der anfægtede denne opfattelse. (Kilde.) Ligesom US Copyright Office evaluerer US Patent and Trademark Office sin holdning. Det er muligt, at USPTO beslutter at gøre intellektuel ejendomsret mere kompleks. AI-skaberne, udviklerne, ejerne kan eje en del af opfindelsen, den hjælper med at skabe. Kunne et ikke-menneske være medejer?
Teknikgiganten Google vejede for nylig. "'Vi mener, at AI ikke bør mærkes som en opfinder under den amerikanske patentlovgivning, og mener, at folk bør have patenter på innovationer, der er skabt ved hjælp af AI," sagde Laura Sheridan, senior patentrådgiver hos Google. I Googles erklæring anbefaler den øget træning og bevidsthed om kunstig intelligens, værktøjerne, risiciene og bedste praksis for patentgranskere. (Kilde.) Hvorfor anvender Patentstyrelsen ikke brugen af AI til at evaluere AI?
AI og fremtiden
AI-egenskaberne og faktisk hele AI-landskabet har ændret sig i løbet af de sidste 12 måneder eller deromkring. Mange virksomheder ønsker at udnytte kraften i AI og høste de foreslåede fordele ved hurtigere og billigere kode og indhold. Både erhvervslivet og loven skal have en bedre forståelse af implikationerne af teknologien, da den vedrører privatliv, intellektuel ejendomsret, patenter og ophavsret. (Billede genereret af ChatGPT med menneskelig prompt "AI and the Future". Bemærk, billedet er ikke ophavsretligt beskyttet).
Opdatering: 17. maj 2023
Der er fortsat udviklinger relateret til AI og loven hver dag. Senatet har et retligt underudvalg for privatliv, teknologi og lovgivning. Det afholder en række høringer om Oversight of AI: Rule for Artificial Intelligence. Det har til hensigt "at skrive reglerne for AI." Med det mål "at afmystificere og holde de nye teknologier ansvarlige for at undgå nogle af fortidens fejltagelser," siger formanden for underudvalget, senator Richard Blumenthal. Interessant nok, for at åbne mødet, afspillede han en dyb falsk lyd, der klonede sin stemme med ChatGPT-indhold trænet på hans tidligere bemærkninger:
Alt for ofte har vi set, hvad der sker, når teknologien overgår reguleringen. Den uhæmmede udnyttelse af personlige data, spredningen af desinformation og uddybningen af samfundsmæssige uligheder. Vi har set, hvordan algoritmiske skævheder kan fastholde diskrimination og fordomme, og hvordan manglen på gennemsigtighed kan underminere offentlighedens tillid. Det er ikke den fremtid, vi ønsker.
Den overvejer en anbefaling om at oprette et nyt reguleringsagentur for kunstig intelligens baseret på modellerne fra Food and Drug Administration (FDA) og Nuclear Regulatory Commission (NRC). (Kilde.) Et af vidnerne for AI-underudvalget foreslog, at AI skulle have licens på samme måde som lægemidler reguleres af FDA. Andre vidner beskriver den nuværende tilstand af AI som det vilde vesten med farer for bias, lidt privatliv og sikkerhedsproblemer. De beskriver en vestverdenens dystopi af maskiner, der er "kraftfulde, hensynsløse og svære at kontrollere."
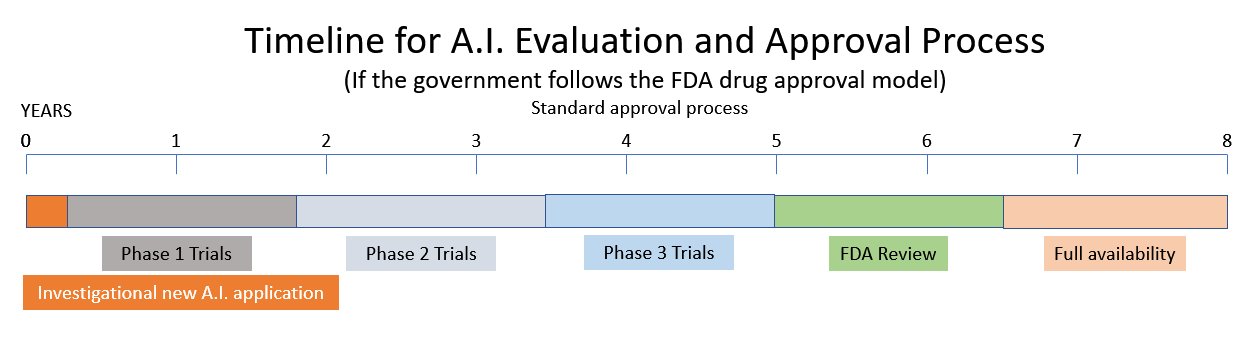
At bringe et nyt lægemiddel på markedet tager 10 – 15 år og en halv milliard dollars. (Kilde.) Så hvis regeringen beslutter sig for at følge NRC's og FDA's modeller, så se efter den seneste tsunami af spændende innovation inden for kunstig intelligens, der i den nærmeste fremtid vil blive erstattet af regeringsregulering og bureaukrati.






.jpg){kind=link}