ШІ: Скринька Пандори або Інновація
Пошук балансу між вирішенням нових питань, які ставить ШІ, та перевагами інновацій
Є дві великі проблеми, пов’язані зі ШІ та інтелектуальною власністю. Одним з них є використання вмісту. Користувач вводить вміст у вигляді підказки, за якою ШІ виконує певну дію. Що відбувається з цим вмістом після відповіді ШІ? Інший – це створення контенту за допомогою ШІ. AI використовує свої алгоритми та базу знань навчальних даних, щоб відповідати на підказку та генерувати результати. Враховуючи той факт, що він був навчений на потенційно захищеному авторським правом матеріалі та іншій інтелектуальній власності, чи є вихідний роман достатньо новим для авторського права?
Використання ШІ інтелектуальної власності
Здається, ШІ та ChatGPT у новинах щодня. ChatGPT, або Generative Pre-trained Transformer, — це чат-бот ШІ, запущений наприкінці 2022 року OpenAI. ChatGPT використовує модель ШІ, навчену за допомогою Інтернету. Некомерційна компанія OpenAI наразі пропонує безкоштовну версію ChatGPT, яку вони називають попередній перегляд дослідження. «Інтерфейс OpenAI можна застосувати практично до будь-якого завдання, яке передбачає розуміння або генерування природної мови, коду або зображень. “ (Source). Крім використання ChatGPT як відкрита розмова з помічником ШІ (або, Марв, саркастичний чат-бот, який неохоче відповідає на запитання), його також можна використовувати для:
- Переклад мов програмування – переклад з однієї мови програмування на іншу.
- Поясніть код – поясніть складний фрагмент коду.
- Напишіть рядок документації Python – напишіть рядок документації для функції Python.
- Виправлення помилок у коді Python – знайдіть і виправте помилки у вихідному коді.
Швидке впровадження ШІ
Розробники програмного забезпечення намагаються інтегрувати ШІ у свої програми. Навколо ChatGPT є кустарне господарство. Деякі створюють програми, які використовують його API. Є навіть один веб-сайт, який називає себе a Торговий майданчик підказок ChatGPT. Вони продають підказки ChatGPT!

Samsung була однією компанією, яка побачила потенціал і підхопила його. Інженер Samsung використовував ChatGPT, щоб допомогти йому налагодити деякий код і допомогти йому виправити помилки. Насправді інженери тричі завантажували корпоративну IP-адресу у вигляді вихідного коду в OpenAI. Samsung дозволив – деякі джерела кажуть, заохочував – своїм інженерам у підрозділі напівпровідників використовувати ChatGPT для оптимізації та виправлення конфіденційного вихідного коду. Після того, як того славнозвісного коня запросили на пасовище, Samsung зачинив двері сараю, обмеживши доступ до вмісту ChatGPT лише твітом і розслідуючи персонал, причетний до витоку даних. Зараз він розглядає можливість створення власного чат-бота. (Зображення, створене ChatGPT – потенційно ненавмисно іронічна, якщо не жартівлива відповідь на підказку: «Команда інженерів програмного забезпечення Samsung використовує OpentAI ChatGPT для налагодження програмного коду, коли вони з подивом і жахом усвідомлюють, що зубна паста вийшла з тюбика і вони оприлюднили корпоративну інтелектуальну власність в Інтернеті».)
Класифікація порушення безпеки як «витік» може бути неправильною. Якщо ви відкриваєте кран, це не витік. Аналогічно, будь-який вміст, який ви вводите в OpenAI, має вважатися публічним. Це ВІДКРИТИЙ ШІ. Його недаремно називають відкритим. Будь-які дані, які ви вводите в ChatGpt, можуть бути використані «для покращення їхніх послуг штучного інтелекту або можуть використовуватися ними та/або навіть їхніми союзними партнерами для різноманітних цілей». (Source.) OpenAI попереджає користувачів у своєму користувачеві керівництво: «Ми не можемо видалити певні підказки з вашої історії. Будь ласка, не діліться будь-якою конфіденційною інформацією у своїх розмовах», – навіть містить застереження ChatGPT відповіді, «зауважте, що інтерфейс чату призначений для демонстрації та не призначений для використання у виробництві».
Samsung — не єдина компанія, яка розкриває приватну, особисту та конфіденційну інформацію. Дослідження компанія виявили, що все, від корпоративних стратегічних документів до імен пацієнтів і медичних діагнозів, було завантажено в ChatGPT для аналізу або обробки. Ці дані використовуються ChatGPT для навчання механізму штучного інтелекту та вдосконалення алгоритмів підказок.
Користувачі здебільшого не знають, як управляється, використовується, зберігається та навіть надається спільний доступ до їх конфіденційної особистої інформації. Онлайн-загрози та вразливі місця в чатах зі штучним інтелектом є серйозними проблемами безпеки, якщо організація та її системи скомпрометовані, особисті дані витікають, викрадаються та використовуються в зловмисних цілях.
Природа спілкування в чаті штучного інтелекту полягає в обробці й аналізі великої кількості даних, у тому числі особистої інформації, для отримання відповідних результатів. Однак використання великих даних, здається, розходиться з концепцією конфіденційності…(Source.)
Це не звинувачення проти ШІ. Це нагадування. Це нагадування, що ШІ слід розглядати як Інтернет. Іншими словами, вважайте будь-яку інформацію, яку ви подаєте в OpenAI, публічною. (Також пам’ятайте, що будь-які результати, створені штучним інтелектом, можна далі трансформувати або використовувати як модель для створення відповідей для майбутніх користувачів.) Це один із способів, у який штучний інтелект порушує інтелектуальну власність і конфіденційність. Інша суперечка полягає в тому, що ШІ використовує матеріали, захищені авторським правом.
ШІ та дилема авторського права
Існує ряд проблем, пов’язаних із добросовісним використанням штучного інтелекту та матеріалами, захищеними авторським правом. ШІ здатний обробляти написане слово. Він може узагальнювати, аналізувати, класифікувати та навіть створювати новий вміст на основі певного стилю написання. ШІ навчається контенту. Я думаю, що йому буде важко уникнути використання захищеного авторським правом матеріалу. Наскільки мені відомо, чинне законодавство не повністю регулює використання захищеного авторським правом контенту для навчання. (зображення)
Я попросив OpenAI набрати текст для першої сторінки «Вбити пересмішника» Гарпер Лі. Це сталося. Отже, я майже впевнений, що він має доступ до захищеного авторським правом тексту. Потім можна створити резюме в стилі Харпер Лі. Або ви можете попросити його створити сонет на тему книги.
| Шекспірівський сонет
На тему «Вбити пересмішника» У місті Мейкомб, де справедливість здається мрією, Молодий Скаут і Джем знаходять істину не по літах. Їх батько, Аттікус, благородна тема Чий моральний компас веде їх через їхні страхи. Том Робінсон, чорний чоловік, помилково звинувачений, Відмовлено в голосі, у справедливому та справедливому суді. Але Аттікус захищає його, не розважаючись, Бо правда і справедливість мають бути нашою справою. Пересмішник, символ чистої благодаті, Невинний у шкоді, його пісня приносить мир. Але зло ховається в цьому маленькому містечку, І справедливість падає, коли ненависть починає зростати. Слова Гарпер Лі, попередження для всіх нас, Боротися за справедливість, щоб це не стало нашим падінням. |
|---|
Немає жодних шансів, що це сплутають із творами Шекспіра – або Харпер Лі. Це трансформаційний новий контент, який явно не слід плутати з оригіналом. Виникає декілька питань. У який момент це стає трансформаційним? Іншими словами, скільки потрібно змінити оригінальний твір, щоб він вважався новим вмістом?
Інше питання – і це однаково стосується будь-якого контенту, створеного штучним інтелектом – кому він належить? Кому належать авторські права на вміст? Або чи може твір навіть бути захищеним авторським правом? Можна навести аргумент, що власником авторських прав має бути особа, яка створила підказку та зробила запит OpenAI. Навколо швидкого авторства виникає нова домашня промисловість. На деяких онлайн-ринках ви можете заплатити від 2 до 20 доларів США за підказки, які отримають створене комп’ютером мистецтво або письмовий текст.
Інші кажуть, що він повинен належати розробнику OpenAI. Це викликає ще більше питань. Чи залежить це від моделі чи механізму, який використовується для створення відповіді?
Я вважаю, що найбільш переконливим аргументом є те, що контент, створений комп’ютером, не може бути захищений авторським правом. Бюро авторських прав США випустило заяву про політику в Федеральний реєстр, березень 2023 р. У ньому йдеться: «Оскільки Офіс отримує приблизно півмільйона заявок на реєстрацію щороку, він бачить нові тенденції в реєстраційній діяльності, які можуть вимагати зміни або розширення інформації, яку необхідно розкрити в заявці». Далі йдеться: «Ці технології, які часто називають «генеративним штучним інтелектом», викликають питання про те, чи створений ними матеріал захищений авторським правом, чи можуть бути зареєстровані роботи, що складаються як з матеріалів, створених людьми, так і зі створених штучним інтелектом, і що заявники, які бажають їх зареєструвати, повинні надати Управлінню інформацію».
«Офіс» визнає, що існують питання, пов’язані із застосуванням закону 150-річної давності до технологій, які не пережили свого першого дня народження. Щоб відповісти на ці питання, Бюро авторських прав запустило ініціативу з вивчення цього питання. Він буде досліджувати та відкритий для публічних коментарів щодо того, як він має розглядати використання захищеного авторським правом контенту під час навчання штучного інтелекту, а також як він має розглядати створений контент.
Команда Федеральний реєстр, дещо дивно, пропонує кольорові коментарі та описує низку цікавих випадків, пов’язаних із «авторством» творів та його історичною політикою щодо авторського права. В одній справі було винесено рішення про те, що мавпа не може мати авторське право. У цьому конкретному випадку мавпи зробили знімки за допомогою камери. Суд постановив, що зображення не можуть бути захищені авторським правом, оскільки Закон про авторське право стосується «дітей», «вдови», «онуків» і «вдівців». В очах суду ця мова виключала мавп. «Існуючі вказівки Управління з реєстрації давно вимагали, щоб роботи були продуктом авторства людини».
Коли OpenAI запитують про суперечку, він відповідає: «Так, існують сірі зони законодавства про інтелектуальну власність, коли йдеться про програмне забезпечення та ШІ. Через складність технології та відсутність усталених правових прецедентів часто важко визначити, які права має автор на свою роботу. Наприклад, якщо алгоритм штучного інтелекту заснований на романі чи існуючій програмі, не завжди зрозуміло, хто володіє правами на алгоритм або оригінальну роботу. Крім того, обсяг патентного захисту для винаходів, пов’язаних зі ШІ, є спірним юридичним питанням».
OpenAI має рацію в цьому. Зрозуміло, що заявка на авторське право в США має бути автором людини. Від сьогодні до кінця року Бюро захисту авторських прав спробує розібратися з деякими запитаннями, що залишилися, і надати додаткові вказівки.
Патентне право та ШІ
Дискусії навколо патентного права США та того, чи охоплює воно винаходи, зроблені штучним інтелектом, – це схожа історія. На даний момент, як написано в законі, патентоздатні винаходи повинні бути зроблені фізичними особами. Верховний суд США відмовився розглядати справу, яка оскаржувала цю думку. (Source.) Як і Бюро авторських прав США, Бюро патентів і торгових марок США оцінює свою позицію. Можливо, USPTO вирішить ускладнити право власності на інтелектуальну власність. Творці, розробники, власники штучного інтелекту можуть володіти частиною винаходу, у створенні якого він допомагає. Чи може нелюдина бути співвласником?
Нещодавно технічний гігант Google зважив. «Ми вважаємо, що штучний інтелект не повинен називатися винахідником відповідно до Закону США про патенти, і вважаємо, що люди повинні мати патенти на інновації, створені за допомогою штучного інтелекту», — сказала Лаура Шерідан, старший патентний радник Google». У заяві Google рекомендує посилити навчання та обізнаність щодо штучного інтелекту, інструментів, ризиків і найкращих практик для патентних експертів. (Source.) Чому Патентне відомство не приймає використання ШІ для оцінки ШІ?
ШІ та майбутнє
Можливості штучного інтелекту та, по суті, весь ландшафт ШІ змінився лише за останні 12 місяців або близько того. Багато компаній хочуть використовувати потужність штучного інтелекту та скористатися пропонованими перевагами швидшого та дешевшого коду та вмісту. І бізнес, і закон повинні краще розуміти наслідки технології, оскільки вона стосується конфіденційності, інтелектуальної власності, патентів і авторського права. (Зображення, створене ChatGPT із підказкою людини «AI and the Future». Зауважте, зображення не захищене авторським правом).
Оновлення: 17 травня 2023 р
Щодня відбуваються події, пов’язані зі штучним інтелектом і законодавством. У Сенаті є судовий підкомітет з питань конфіденційності, технологій і права. Він проводить серію слухань на тему «Нагляд за ШІ: правило для штучного інтелекту». Він має намір «написати правила ШІ». Голова підкомітету, сенатор Річард Блюменталь, каже, що має на меті «демістифікувати та притягнути до відповідальності ці нові технології, щоб уникнути деяких помилок минулого». Цікаво, що на початку зустрічі він відтворив глибоке фальшиве аудіо, клонуючи свій голос із вмістом ChatGPT, навченим на його попередні зауваження:
Занадто часто ми бачили, що відбувається, коли технології випереджають регулювання. Нестримна експлуатація персональних даних, поширення дезінформації та поглиблення суспільної нерівності. Ми бачили, як алгоритмічні упередження можуть увічнити дискримінацію та упередження, а також як відсутність прозорості може підірвати довіру суспільства. Це не те майбутнє, якого ми хочемо.
Він розглядає рекомендацію щодо створення нового Агентства з регулювання штучного інтелекту на основі моделей Управління з контролю за продуктами й ліками (FDA) і Комісії з ядерного регулювання (NRC). (Source.) Один зі свідків перед підкомітетом ШІ припустив, що ШІ слід ліцензувати так само, як фармацевтичні препарати регулюються FDA. Інші свідки описують поточний стан штучного інтелекту як Дикий Захід з небезпекою упередженості, недостатньою конфіденційністю та проблемами безпеки. Вони описують антиутопію західного світу машин, які є «потужними, безрозсудними і ними важко керувати».
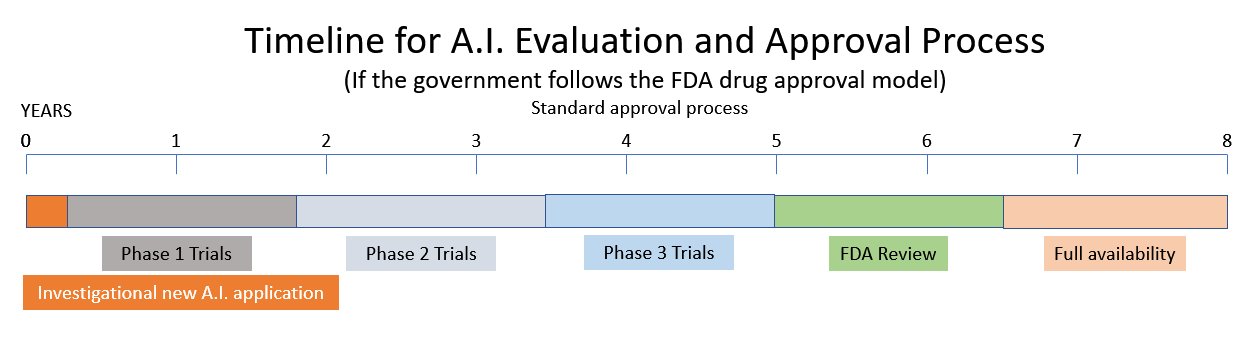
Щоб вивести новий препарат на ринок, потрібно 10-15 років і півмільярда доларів. (Source.) Отже, якщо уряд вирішить наслідувати моделі NRC і FDA, очікуйте, що нещодавнє цунамі захоплюючих інновацій у сфері штучного інтелекту буде замінено в найближчому майбутньому державним регулюванням і бюрократизмом.






.jpg){kind=link}