AI: Pandorina kutija ili inovacija
Pronalaženje ravnoteže između rješavanja novih pitanja koja AI postavlja i prednosti inovacija
Postoje dva velika problema vezana za AI i intelektualnu svojinu. Jedna je njegova upotreba sadržaja. Korisnik unosi sadržaj u obliku prompta na kojem AI izvodi neku radnju. Šta se dešava sa tim sadržajem nakon što AI odgovori? Drugi je AI kreiranje sadržaja. AI koristi svoje algoritme i bazu znanja podataka o obuci da odgovori na upit i generiše izlaz. Uzimajući u obzir činjenicu da je obučen o potencijalno zaštićenom materijalu i drugom intelektualnom vlasništvu, da li je izlazni roman dovoljan za autorska prava?
AI korištenje intelektualnog vlasništva
Čini se da su AI i ChatGPT svakodnevno u vijestima. ChatGPT, ili Generative Pre-trained Transformer, je AI chatbot pokrenut krajem 2022. OpenAI. ChatGPT koristi AI model koji je obučen korištenjem interneta. Neprofitna kompanija OpenAI trenutno nudi besplatnu verziju ChatGPT-a koju nazivaju pregled istraživanja. „API OpenAI može se primijeniti na gotovo svaki zadatak koji uključuje razumijevanje ili generiranje prirodnog jezika, koda ili slika. “ (izvor). Pored upotrebe Chat GPT kao otvoreni razgovor sa i AI asistentom (ili, Marv, sarkastičan chat bot koji nevoljko odgovara na pitanja), može se koristiti i za:
- Prevođenje programskih jezika – Prevedite s jednog programskog jezika na drugi.
- Objasni kod – Objasnite komplikovani deo koda.
- Write a docstring Python – Napišite docstring za Python funkciju.
- Popravi greške u Python kodu – Pronađite i popravite greške u izvornom kodu.
Brzo usvajanje AI
Softverske kompanije se trude da integrišu AI u svoje aplikacije. Oko ChatGPT-a postoji domaća industrija. Neki kreiraju aplikacije koje koriste njegove API-je. Postoji čak i jedna web stranica koja se naplaćuje kao a ChatGPT brzo tržište. Oni prodaju ChatGPT upite!

Samsung bila je jedna kompanija koja je uvidjela potencijal i skočila na vagon. Inženjer u Samsung-u je koristio ChatGPT da mu pomogne u otklanjanju grešaka u nekom kodu i pomoći mu da popravi greške. Zapravo, inženjeri su u tri odvojena navrata otpremili korporativni IP u obliku izvornog koda u OpenAI. Samsung je dozvolio – neki izvori kažu, ohrabrio – svojim inženjerima u sektoru poluprovodnika da koriste ChatGPT za optimizaciju i popravku povjerljivog izvornog koda. Nakon što je taj poslovični konj pozvan na pašu, Samsung je zalupio vrata štale ograničivši sadržaj koji se dijeli s ChatGPT-om na manje od tvita i istražujući osoblje uključeno u curenje podataka. Sada razmišlja o izgradnji vlastitog chat bota. (Slika koju je generirao ChatGPT – potencijalno nenamjerno ironičan, ako ne i duhovit, odgovor na upit, „tim Samsung softverskih inženjera koji koristi OpentAI ChatGPT za otklanjanje grešaka u softverskom kodu kada s iznenađenjem i užasom shvate da je pasta za zube izašla iz tube i izložili su korporativnu intelektualnu svojinu internetu.”)
Klasifikacija kršenja sigurnosti kao „curenja“ može biti pogrešan naziv. Ako otvorite slavinu, to nije curenje. Analogno tome, svaki sadržaj koji unesete u OpenAI treba se smatrati javnim. To je OTVORENA AI. Zove se otvorenim s razlogom. Svi podaci koje unesete u ChatGpt mogu se koristiti „za poboljšanje njihovih usluga umjetne inteligencije ili ih mogu koristiti oni i/ili čak njihovi partneri u različite svrhe“. (izvor.) OpenAI upozorava korisnike u svom korisniku vodič: “Nismo u mogućnosti da izbrišemo određene upite iz vaše historije. Nemojte dijeliti nikakve osjetljive informacije u svojim razgovorima,” ChatGPT čak uključuje upozorenje u svom odgovori, “imajte na umu da je sučelje za ćaskanje namijenjeno kao demonstracija i da nije namijenjeno za proizvodnju.”
Samsung nije jedina kompanija koja objavljuje vlasničke, lične i povjerljive informacije u divljinu. Istraživanje društvo otkrili su da je sve, od korporativnih strateških dokumenata do imena pacijenata i medicinske dijagnoze, učitano u ChatGPT radi analize ili obrade. ChatGPT koristi te podatke za treniranje AI motora i za preciziranje algoritama brze obrade.
Korisnici uglavnom ne znaju kako se njihovim osjetljivim ličnim identifikacijskim informacijama upravlja, koriste, pohranjuju ili čak dijele. Pretnje i ranjivosti na mreži u ćaskanju sa veštačkom inteligencijom su značajna bezbednosna pitanja ako su organizacija i njeni sistemi kompromitovani, lični podaci procure, ukradeni i korišćeni u zlonamerne svrhe.
Priroda AI ćaskanja je da obrađuje i analizira veliku količinu podataka, uključujući lične podatke, kako bi se proizveli relevantni rezultati. Međutim, čini se da upotreba velikih podataka odstupa od koncepta privatnosti...(izvor.)
Ovo nije optužnica protiv AI. To je podsjetnik. To je podsjetnik da AI treba tretirati kao internet. Drugim riječima, svaku informaciju koju unesete u OpenAI smatrajte javnom. (Zapamtite, takođe, da se svaki rezultat koji generiše AI može dalje transformisati ili koristiti kao model za generisanje odgovora za buduće korisnike.) To je jedan od načina na koji AI ugrožava intelektualno vlasništvo i privatnost. Još jedna kontroverza je korištenje materijala zaštićenog autorskim pravima od strane umjetne inteligencije.
AI i dilema o autorskim pravima
Postoji niz zabrinutosti u vezi sa poštenom upotrebom AI i materijalom zaštićenim autorskim pravima. AI je sposoban za obradu pisane riječi. Može rezimirati, analizirati, kategorizirati, pa čak i kreirati novi sadržaj na osnovu određenog stila pisanja. AI je obučen za sadržaj. Mislim da bi mu bilo teško izbjeći konzumiranje materijala zaštićenog autorskim pravima. Koliko ja znam, trenutni zakon ne reguliše u potpunosti korišćenje sadržaja zaštićenog autorskim pravima za obuku. (slika)
Zamolio sam OpenAI da otkuca tekst za prvu stranicu knjige “To Kill a Mockingbird” od Harper Lee. Jeste. Dakle, prilično sam siguran da ima pristup tekstu zaštićenom autorskim pravima. Zatim može kreirati životopis u stilu Harper Lee. Ili ga možete zamoliti da napravi sonet na osnovu teme knjige.
| Šekspirov sonet
Zasnovan na temi "Ubiti pticu rugalicu" U Maycombovom gradu gdje se pravda čini san, Mladi Scout i Jem pronalaze istinu izvan svojih godina. Njihov otac, Atticus, plemenita tema Čiji ih moralni kompas vodi kroz njihove strahove. Tom Robinson, lažno optužen crnac, Uskraćen glas, suđenje koje je pravedno i pošteno. Ali Atticus ga brani, ne zabavljajući se, Jer istina i pravda moraju biti naša stvar. Ptica rugalica, simbol čiste milosti, Nevina na štetu, njena pjesma donosi mir. Ali zlo vreba u prostoru ovog malog grada, I pravda pada kako mržnja počinje da raste. Riječi Harper Lee, upozorenje svima nama, Da se borimo za pravdu, da ne bude naš pad. |
|---|
Nema šanse da se ovo pogreši sa Šekspirovim delom – ili sa Harper Li u tom smislu. To je transformacijski novi sadržaj koji se očito ne smije brkati s originalom. Postavlja se nekoliko pitanja. U kom trenutku to postaje transformaciono? Drugim riječima, koliko je originalno djelo potrebno promijeniti da bi se smatralo novim sadržajem?
Drugo pitanje – a to se podjednako odnosi i na bilo koji sadržaj kreiran od strane AI – ko ga posjeduje? Ko posjeduje autorska prava na sadržaj? Ili, može li djelo uopće biti zaštićeno autorskim pravima? Može se iznijeti argument da bi vlasnik autorskih prava trebao biti pojedinac koji je kreirao prompt i podnio zahtjev OpenAI. Postoji nova domaća industrija oko brzog autorstva. Na nekim internetskim tržištima možete platiti između 2 i 20 dolara za upite koji će vam dati kompjuterski generiranu umjetnost ili pisani tekst.
Drugi kažu da bi trebalo da pripada programeru OpenAI. To otvara još više pitanja. Zavisi li to od modela ili motora koji se koristi za generiranje odgovora?
Mislim da je najuvjerljiviji argument da sadržaj koji generiše kompjuter ne može biti zaštićen autorskim pravima. Američki ured za autorska prava izdao je izjavu o politici u Federalni registar, mart 2023. U njemu se navodi: “Budući da Ured prima otprilike pola miliona zahtjeva za registraciju svake godine, uočava nove trendove u registracijskim aktivnostima koje mogu zahtijevati izmjenu ili proširenje informacija koje se trebaju objaviti u aplikaciji.” Dalje se kaže: „Ove tehnologije, koje se često opisuju kao 'generativna AI', postavljaju pitanja o tome da li je materijal koji proizvode zaštićen autorskim pravima, mogu li se registrovati djela koja se sastoje i od materijala koje su autori ljudi i od AI-a i šta Podnosioci zahtjeva koji žele da ih registruju trebaju dostaviti Uredu informacije.”
“Ured” priznaje da postoje pitanja vezana za primjenu 150 godina starog zakona na tehnologiju koja nije dočekala svoj prvi rođendan. Kako bi riješio ta pitanja, Ured za autorska prava pokrenuo je inicijativu za proučavanje ovog problema. Istražit će i otvoriti komentare javnosti o tome kako treba da se bavi upotrebom sadržaja zaštićenog autorskim pravima u obuci AI, kao i kako treba uzeti u obzir sadržaj koji se generiše.
The Savezni registar, pomalo iznenađujuće, nudi komentare u boji i opisuje niz zanimljivih slučajeva vezanih za “autorstvo” djela i njegove istorijske politike o autorskim pravima. Jedan slučaj koji je presuđen tvrdi da majmun ne može imati autorska prava. U ovom konkretnom slučaju, majmuni su snimili slike kamerom. Sud je odlučio da slike ne mogu biti zaštićene autorskim pravima jer se Zakon o autorskim pravima odnosi na autorovu "djecu", "udovicu", "unuke" i "udovce". U očima suda, ovaj jezik je isključio majmune. “Postojeće smjernice Ureda za registraciju već dugo zahtijevaju da djela budu proizvod ljudskog autorstva.”
Kada je OpenAI upitan o kontroverzi, on kaže: „Da, postoje sive zone zakona o intelektualnoj svojini kada su u pitanju softver i AI. Zbog složenosti tehnologije i nedostatka uspostavljenih pravnih presedana, često je teško odrediti koja prava kreator ima na svoj rad. Na primjer, ako je AI algoritam zasnovan na novom ili postojećem softverskom programu, nije uvijek jasno ko posjeduje prava na algoritam ili originalno djelo. Osim toga, obim patentne zaštite za izume povezane s umjetnom inteligencijom je sporno pravno pitanje.”
OpenAI je u pravu za ovo. Jasno je da američka prijava za autorska prava mora imati ljudsko autorstvo. Od sada do kraja godine, Ured za autorska prava će pokušati riješiti neka od preostalih pitanja i dati dodatne smjernice.
Zakon o patentima i AI
Slična je priča o američkom zakonu o patentima i o tome da li on pokriva izume koje je napravila AI. Trenutno, kako je zakon napisan, patentibilne izume moraju napraviti fizička lica. Vrhovni sud SAD odbio je da sasluša predmet koji je osporio tu ideju. (izvor.) Kao i Ured za autorska prava SAD, Ured za patente i žigove SAD procjenjuje svoju poziciju. Moguće je da USPTO odluči da vlasništvo nad intelektualnom svojinom učini složenijim. Kreatori umjetne inteligencije, programeri, vlasnici mogu posjedovati dio izuma koji pomaže u stvaranju. Može li ne-čovek biti suvlasnik?
Tehnološki gigant Google se nedavno oglasio. “Vjerujemo da AI ne treba biti označena kao izumitelj prema američkom zakonu o patentima i vjerujemo da bi ljudi trebali posjedovati patente za inovacije koje su nastale uz pomoć AI”, rekla je Laura Sheridan, viši savjetnik za patente u Googleu. U Googleovoj izjavi, preporučuje se povećana obuka i svijest o AI, alatima, rizicima i najboljim praksama za ispitivače patenata. (izvor.) Zašto Ured za patente ne usvoji korištenje AI za procjenu AI?
AI i budućnost
Mogućnosti AI i, zapravo, čitav AI krajolik su se promijenile u samo posljednjih 12 mjeseci ili tako nešto. Mnoge kompanije žele iskoristiti moć AI i iskoristiti predložene prednosti bržeg i jeftinijeg koda i sadržaja. I biznis i zakon moraju bolje razumjeti implikacije tehnologije u pogledu privatnosti, intelektualnog vlasništva, patenata i autorskih prava. (Sliku generisao ChatGPT sa ljudskim upitom „AI i budućnost“. Napomena, slika nije zaštićena autorskim pravima).
Ažuriranje: 17. maj 2023
Svakodnevno se nastavljaju dešavanja u vezi sa AI i zakonom. Senat ima Pravosudni pododbor za privatnost, tehnologiju i zakon. Održava seriju saslušanja na temu Nadzor nad umjetnom inteligencijom: Pravilo za umjetnu inteligenciju. Namjerava "napisati pravila AI". S ciljem "demistifikovati i pozvati na odgovornost te nove tehnologije kako bi se izbjegle neke od grešaka iz prošlosti", kaže predsjednik podkomiteta, senator Richard Blumenthal. Zanimljivo, da bi otvorio sastanak, pustio je duboki lažni audio klonirajući svoj glas s ChatGPT sadržajem obučenim na njegovim prethodnim primjedbama:
Prečesto smo vidjeli šta se dešava kada tehnologija nadmaši regulativu. Neobuzdana eksploatacija ličnih podataka, proliferacija dezinformacija i produbljivanje društvenih nejednakosti. Vidjeli smo kako algoritamske predrasude mogu produžiti diskriminaciju i predrasude i kako nedostatak transparentnosti može potkopati povjerenje javnosti. Ovo nije budućnost koju želimo.
Razmatra preporuku za stvaranje nove Regulatorne agencije za umjetnu inteligenciju zasnovanu na modelima Uprave za hranu i lijekove (FDA) i Nuklearne regulatorne komisije (NRC). (izvor.) Jedan od svjedoka pred podkomitetom za umjetnu inteligenciju sugerirao je da bi umjetna umjetna inteligencija trebala biti licencirana na sličan način kao što farmaceutske proizvode reguliše FDA. Drugi svjedoci opisuju trenutno stanje AI kao Divlji zapad s opasnostima od pristrasnosti, malo privatnosti i sigurnosnih problema. Oni opisuju distopiju Zapadnog svijeta o mašinama koje su “moćne, nepromišljene i koje je teško kontrolisati”.
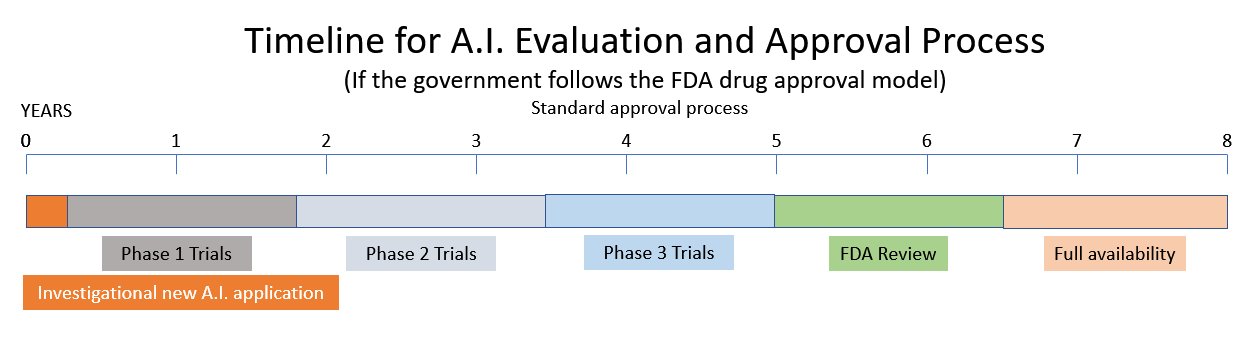
Za izvođenje novog lijeka na tržište potrebno je 10-15 godina i pola milijarde dolara. (izvor.) Dakle, ako Vlada odluči slijediti modele NRC-a i FDA-e, potražite nedavni cunami uzbudljivih inovacija u oblasti umjetne inteligencije koji će u bliskoj budućnosti biti zamijenjen državnim propisom i birokratijom.






.jpg){kind=link}