KI: Büchse der Pandora oder Innovation
Ein Gleichgewicht zwischen der Lösung der neuen Fragen, die KI aufwirft, und den Vorteilen von Innovationen finden
Es gibt zwei große Probleme im Zusammenhang mit KI und geistigem Eigentum. Einer davon ist die Verwendung von Inhalten. Der Benutzer gibt Inhalte in Form einer Eingabeaufforderung ein, woraufhin die KI eine Aktion ausführt. Was passiert mit diesem Inhalt, nachdem die KI reagiert hat? Das andere ist die Erstellung von Inhalten durch KI. KI nutzt ihre Algorithmen und ihre Wissensbasis aus Trainingsdaten, um auf eine Aufforderung zu reagieren und eine Ausgabe zu generieren. Ist das Ergebnis angesichts der Tatsache, dass es auf potenziell urheberrechtlich geschütztes Material und anderes geistiges Eigentum trainiert wurde, ausreichend, um urheberrechtlich geschützt zu sein?
Nutzung von geistigem Eigentum durch KI
Es scheint, als wären KI und ChatGPT jeden Tag in den Nachrichten. ChatGPT, oder Generative Pre-trained Transformer, ist ein KI-Chatbot, der Ende 2022 von eingeführt wurde OpenAI. ChatGPT verwendet ein KI-Modell, das mithilfe des Internets trainiert wurde. Das gemeinnützige Unternehmen OpenAI bietet derzeit eine kostenlose Version von ChatGPT an, die sie nennen Forschungsvorschau. „Die OpenAI-API kann auf praktisch jede Aufgabe angewendet werden, bei der es darum geht, natürliche Sprache, Code oder Bilder zu verstehen oder zu generieren. „(Quelle). Zusätzlich zur Verwendung ChatGPT als offenes Gespräch mit einem KI-Assistenten (oder, Marv, ein sarkastischer Chatbot, der widerwillig Fragen beantwortet), kann es auch verwendet werden, um:
- Programmiersprachen übersetzen – Übersetzen Sie von einer Programmiersprache in eine andere.
- Code erklären – Erklären Sie einen komplizierten Code.
- Schreiben Sie einen Python-Dokumentstring – Schreiben Sie einen Dokumentstring für eine Python-Funktion.
- Fehler im Python-Code beheben – Fehler im Quellcode finden und beheben.
Die schnelle Einführung von KI
Softwareunternehmen bemühen sich darum, KI in ihre Anwendungen zu integrieren. Rund um ChatGPT gibt es eine Heimindustrie. Einige erstellen Anwendungen, die ihre APIs nutzen. Es gibt sogar eine Website, die sich selbst als bezeichnet ChatGPT-Prompt-Marktplatz. Sie verkaufen ChatGPT-Eingabeaufforderungen!

Samsung war ein Unternehmen, das das Potenzial erkannte und auf den Zug aufsprang. Ein Ingenieur bei Samsung nutzte ChatGPT, um ihm beim Debuggen von Code und beim Beheben der Fehler zu helfen. Tatsächlich haben Ingenieure dreimal Unternehmens-IP in Form von Quellcode auf OpenAI hochgeladen. Samsung erlaubte seinen Ingenieuren in der Halbleiterabteilung, ChatGPT zu verwenden, um vertraulichen Quellcode zu optimieren und zu reparieren – einige Quellen sagen, Samsung habe es ermutigt. Nachdem das sprichwörtliche Pferd auf die Weide eingeladen worden war, schlug Samsung die Scheunentür zu, indem es die mit ChatGPT geteilten Inhalte auf weniger als einen Tweet beschränkte und die an dem Datenleck beteiligten Mitarbeiter untersuchte. Es wird nun darüber nachgedacht, einen eigenen Chatbot zu entwickeln. (Bild generiert von ChatGPT – eine möglicherweise unbeabsichtigt ironische, wenn nicht sogar humorvolle Antwort auf die Aufforderung: „Ein Team von Samsung-Softwareentwicklern verwendet OpentAI ChatGPT, um Softwarecode zu debuggen, als sie mit Überraschung und Entsetzen feststellen, dass die Zahnpasta aus der Tube ist und Sie haben geistiges Eigentum von Unternehmen dem Internet zugänglich gemacht.“)
Die Einstufung der Sicherheitsverletzung als „Leck“ könnte eine Fehlbezeichnung sein. Wenn Sie einen Wasserhahn aufdrehen, handelt es sich nicht um ein Leck. Analog dazu sollten alle Inhalte, die Sie in OpenAI eingeben, als öffentlich gelten. Das ist OPEN AI. Es heißt nicht ohne Grund „offen“. Alle Daten, die Sie in ChatGpt eingeben, können „zur Verbesserung ihrer KI-Dienste oder von ihnen und/oder sogar ihren verbündeten Partnern für verschiedene Zwecke verwendet werden“. (Quelle.) OpenAI warnt Benutzer in seinem Benutzerverzeichnis Guide: „Wir können bestimmte Eingabeaufforderungen nicht aus Ihrem Verlauf löschen. Bitte geben Sie in Ihren Gesprächen keine vertraulichen Informationen weiter“, fügt ChatGPT sogar eine Einschränkung hinzu Antworten„Bitte beachten Sie, dass die Chat-Oberfläche als Demonstration gedacht ist und nicht für den produktiven Einsatz bestimmt ist.“
Samsung ist nicht das einzige Unternehmen, das proprietäre, persönliche und vertrauliche Informationen an die Öffentlichkeit weitergibt. Eine Forschung Unternehmen stellte fest, dass alles, von unternehmensstrategischen Dokumenten bis hin zu Patientennamen und medizinischen Diagnosen, zur Analyse oder Verarbeitung in ChatGPT geladen wurde. Diese Daten werden von ChatGPT verwendet, um die KI-Engine zu trainieren und die Eingabeaufforderungsalgorithmen zu verfeinern.
Benutzer wissen meist nicht, wie ihre sensiblen persönlichen Identifikationsdaten verwaltet, verwendet, gespeichert oder sogar weitergegeben werden. Online-Bedrohungen und Schwachstellen beim KI-Chatten stellen ein erhebliches Sicherheitsrisiko dar, wenn ein Unternehmen und seine Systeme kompromittiert werden, persönliche Daten durchsickern, gestohlen und für böswillige Zwecke verwendet werden.
Die Natur des KI-Chats besteht darin, große Datenmengen, einschließlich persönlicher Informationen, zu verarbeiten und zu analysieren, um relevante Ergebnisse zu erzielen. Allerdings scheint die Nutzung von Big Data vom Konzept der Privatsphäre abzuweichen…(Quelle.)
Dies ist keine Anklage gegen KI. Es ist eine Erinnerung. Es ist eine Erinnerung daran, dass KI wie das Internet behandelt werden sollte. Mit anderen Worten: Betrachten Sie alle Informationen, die Sie in OpenAI einspeisen, als öffentlich. (Denken Sie auch daran, dass jede durch KI erzeugte Ausgabe weiter transformiert oder als Modell verwendet werden kann, um Antworten für zukünftige Benutzer zu generieren.) Auf diese Weise gefährdet KI geistiges Eigentum und Privatsphäre. Eine weitere Kontroverse ist die Verwendung von urheberrechtlich geschütztem Material durch KI.
KI und das Urheberrechtsdilemma
Es gibt eine Reihe von Bedenken im Zusammenhang mit der fairen Nutzung von KI und urheberrechtlich geschütztem Material. KI ist in der Lage, das geschriebene Wort zu verarbeiten. Es kann basierend auf einem bestimmten Schreibstil Inhalte zusammenfassen, analysieren, kategorisieren und sogar neue erstellen. KI wird auf Inhalte trainiert. Ich denke, es wäre schwierig, den Konsum von urheberrechtlich geschütztem Material zu vermeiden. Soweit mir bekannt ist, regelt das geltende Recht die Verwendung urheberrechtlich geschützter Inhalte für Schulungen nicht vollständig. (Bild)
Ich habe OpenAI gebeten, den Text für die erste Seite von „To Kill a Mockingbird“ von Harper Lee einzugeben. Das tat es. Ich bin mir also ziemlich sicher, dass es Zugriff auf den urheberrechtlich geschützten Text hat. Anschließend kann ein Lebenslauf im Stil von Harper Lee erstellt werden. Oder Sie können es bitten, ein Sonett basierend auf dem Thema des Buches zu erstellen.
| Ein Shakespeare-Sonett
Basierend auf dem Thema „Eine Spottdrossel töten“ In Maycombs Stadt, wo Gerechtigkeit ein Traum zu sein scheint, Young Scout und Jem finden die Wahrheit, die über ihr Alter hinausgeht. Ihr Vater Atticus, ein edles Thema Deren moralischer Kompass sie durch ihre Ängste führt. Tom Robinson, ein fälschlicherweise beschuldigter Schwarzer, Eine Stimme verweigert, ein Prozess, der gerecht und fair ist. Aber Atticus verteidigt ihn, nicht erfreut, Denn Wahrheit und Gerechtigkeit müssen unsere Angelegenheit sein. Die Spottdrossel, ein Symbol reiner Gnade, Ohne Schaden zuzufügen, bringt sein Lied Frieden. Aber im Raum dieser kleinen Stadt lauert das Böse, Und die Gerechtigkeit sinkt, während der Hass zunimmt. Harper Lees Worte, eine Warnung an uns alle, Für Gerechtigkeit kämpfen, damit es nicht unser Untergang wird. |
|---|
Es besteht keine Chance, dass dies mit Shakespeares Werk verwechselt wird – oder auch mit dem von Harper Lee. Es handelt sich um transformative neue Inhalte, die offensichtlich nicht mit dem Original verwechselt werden dürfen. Es stellen sich mehrere Fragen. An welchem Punkt wird es transformativ? Mit anderen Worten: Wie stark muss das Originalwerk verändert werden, damit es als neuer Inhalt gilt?
Eine weitere Frage – und das gilt gleichermaßen für alle von KI erstellten Inhalte – wem gehört sie? Wem gehört das Urheberrecht an den Inhalten? Oder kann das Werk überhaupt urheberrechtlich geschützt sein? Man kann argumentieren, dass der Inhaber des Urheberrechts die Person sein sollte, die die Aufforderung erstellt und die Anfrage an OpenAI gestellt hat. Es gibt eine neue Heimindustrie rund um das Prompt Authoring. Auf einigen Online-Marktplätzen können Sie zwischen 2 und 20 US-Dollar für Eingabeaufforderungen bezahlen, mit denen Sie computergenerierte Kunst oder geschriebenen Text erhalten.
Andere sagen, es sollte dem Entwickler von OpenAI gehören. Das wirft noch mehr Fragen auf. Hängt es vom Modell oder der Engine ab, die zum Generieren der Antwort verwendet wird?
Meiner Meinung nach ist das überzeugendste Argument, dass von einem Computer generierte Inhalte nicht urheberrechtlich geschützt sein können. Das US Copyright Office hat eine Grundsatzerklärung herausgegeben Bundesregister, März 2023. Darin heißt es: „Da das Amt jedes Jahr etwa eine halbe Million Registrierungsanträge erhält, sieht es neue Trends in der Registrierungsaktivität, die möglicherweise eine Änderung oder Erweiterung der in einem Antrag offenzulegenden Informationen erforderlich machen.“ Weiter heißt es: „Diese Technologien, die oft als ‚generative KI‘ bezeichnet werden, werfen Fragen auf, ob das von ihnen produzierte Material urheberrechtlich geschützt ist, ob Werke, die sowohl aus von Menschen erstelltem als auch aus KI-generiertem Material bestehen, registriert werden dürfen und was.“ Antragsteller, die sie registrieren lassen möchten, sollten dem Amt entsprechende Informationen zur Verfügung stellen.“
„The Office“ räumt ein, dass es Fragen im Zusammenhang mit der Anwendung eines 150 Jahre alten Gesetzes auf eine Technologie gibt, die ihren ersten Geburtstag noch nicht erlebt hat. Um diese Fragen zu beantworten, startete das Copyright Office eine Initiative zur Untersuchung des Problems. Es wird untersucht und öffentlich kommentiert, wie es mit der Verwendung urheberrechtlich geschützter Inhalte beim Training von KI umgehen sollte und wie es die generierten Inhalte berücksichtigen sollte.
Das Bundesregister, Etwas überraschend bietet es einige farbige Kommentare und beschreibt eine Reihe interessanter Fälle im Zusammenhang mit der „Urheberschaft“ von Werken und ihren historischen Richtlinien zum Urheberrecht. In einem entschiedenen Fall wurde festgestellt, dass ein Affe kein Urheberrecht besitzen kann. In diesem speziellen Fall haben Affen Bilder mit einer Kamera aufgenommen. Das Gericht entschied, dass die Bilder nicht urheberrechtlich geschützt sein könnten, da sich das Urheberrechtsgesetz auf die „Kinder“, „Witwe“, „Enkel“ und „Witwer“ eines Autors bezieht. Nach Ansicht des Gerichts schloss diese Sprache Affen aus. „Die bestehenden Registrierungsrichtlinien des Amtes verlangen seit langem, dass Werke das Produkt menschlicher Urheberschaft sein müssen.“
Als OpenAI auf die Kontroverse angesprochen wird, heißt es: „Ja, es gibt Grauzonen im Recht des geistigen Eigentums, wenn es um Software und KI geht.“ Aufgrund der Komplexität der Technologie und des Fehlens etablierter rechtlicher Präzedenzfälle ist es oft schwierig zu bestimmen, welche Rechte ein Urheber an seinem Werk hat. Wenn beispielsweise ein KI-Algorithmus auf einem Roman oder einem bestehenden Softwareprogramm basiert, ist nicht immer klar, wer die Rechte an dem Algorithmus oder dem Originalwerk besitzt. Darüber hinaus ist der Umfang des Patentschutzes für KI-bezogene Erfindungen eine umstrittene Rechtsfrage.“
Da hat OpenAI Recht. Es ist klar, dass ein US-amerikanischer Urheberrechtsantrag eine menschliche Urheberschaft haben muss. Bis Ende des Jahres wird das Copyright Office versuchen, einige der verbleibenden Fragen zu klären und zusätzliche Hinweise bereitzustellen.
Patentrecht und KI
Ähnlich verhält es sich mit den Diskussionen über das US-Patentrecht und die Frage, ob es Erfindungen durch KI abdeckt. Derzeit ist es gesetzlich vorgeschrieben, dass patentierbare Erfindungen von natürlichen Personen gemacht werden müssen. Der Oberste Gerichtshof der USA weigerte sich, einen Fall anzuhören, der diese Auffassung in Frage stellte. (Quelle.) Wie das US Copyright Office prüft auch das US Patent and Trademark Office seine Position. Es ist möglich, dass das USPTO beschließt, den Besitz von geistigem Eigentum komplexer zu gestalten. Die Schöpfer, Entwickler und Eigentümer der KI können einen Teil der Erfindung besitzen, zu deren Entstehung sie beiträgt. Könnte ein Nichtmensch Miteigentümer sein?
Der Technologieriese Google hat sich kürzlich geäußert. „‚Wir glauben, dass KI nach dem US-Patentrecht nicht als Erfinder abgestempelt werden sollte und glauben, dass Menschen Patente auf Innovationen besitzen sollten, die mit Hilfe von KI hervorgebracht wurden‘, sagte Laura Sheridan, leitende Patentanwältin bei Google.“ In der Erklärung von Google wird eine verstärkte Schulung und Sensibilisierung der Patentprüfer für KI, die Tools, die Risiken und Best Practices empfohlen. (Quelle.) Warum übernimmt das Patentamt nicht den Einsatz von KI zur Bewertung von KI?
KI und die Zukunft
Die Fähigkeiten der KI und tatsächlich die gesamte KI-Landschaft haben sich in den letzten etwa 12 Monaten verändert. Viele Unternehmen möchten die Leistungsfähigkeit der KI nutzen und die Vorteile eines schnelleren und günstigeren Codes und Inhalts nutzen. Sowohl die Wirtschaft als auch das Gesetz müssen die Auswirkungen der Technologie auf Datenschutz, geistiges Eigentum, Patente und Urheberrecht besser verstehen. (Von ChatGPT mit der menschlichen Eingabeaufforderung „KI und die Zukunft“ generiertes Bild. Beachten Sie, dass das Bild nicht urheberrechtlich geschützt ist.)
Update: 17. Mai 2023
Es gibt weiterhin täglich Entwicklungen rund um KI und Recht. Der Senat verfügt über einen Justizunterausschuss für Datenschutz, Technologie und Recht. Es veranstaltet eine Reihe von Anhörungen zum Thema „Aufsicht über KI: Regel für künstliche Intelligenz“. Es beabsichtigt, „die Regeln der KI zu schreiben“. Mit dem Ziel, „diese neuen Technologien zu entmystifizieren und zur Verantwortung zu ziehen, um einige der Fehler der Vergangenheit zu vermeiden“, sagt der Vorsitzende des Unterausschusses, Senator Richard Blumenthal. Interessanterweise spielte er zur Eröffnung des Meetings ein Deep-Fake-Audio ab, das seine Stimme mit ChatGPT-Inhalten klonte, die auf seinen vorherigen Bemerkungen basierten:
Zu oft haben wir gesehen, was passiert, wenn die Technologie die Regulierung übertrifft. Die ungezügelte Ausbeutung personenbezogener Daten, die Verbreitung von Desinformation und die Vertiefung gesellschaftlicher Ungleichheiten. Wir haben gesehen, wie algorithmische Vorurteile Diskriminierung und Vorurteile aufrechterhalten können und wie mangelnde Transparenz das Vertrauen der Öffentlichkeit untergraben kann. Das ist nicht die Zukunft, die wir wollen.
Es erwägt eine Empfehlung zur Schaffung einer neuen Regulierungsbehörde für künstliche Intelligenz auf der Grundlage der Modelle der Food and Drug Administration (FDA) und der Nuclear Regulatory Commission (NRC). (Quelle.) Einer der Zeugen vor dem KI-Unterausschuss schlug vor, dass KI auf ähnliche Weise lizenziert werden sollte, wie Arzneimittel von der FDA reguliert werden. Andere Zeugen beschreiben den aktuellen Zustand der KI als den Wilden Westen mit der Gefahr von Voreingenommenheit, wenig Privatsphäre und Sicherheitsproblemen. Sie beschreiben eine Westwelt-Dystopie von Maschinen, die „mächtig, rücksichtslos und schwer zu kontrollieren“ sind.
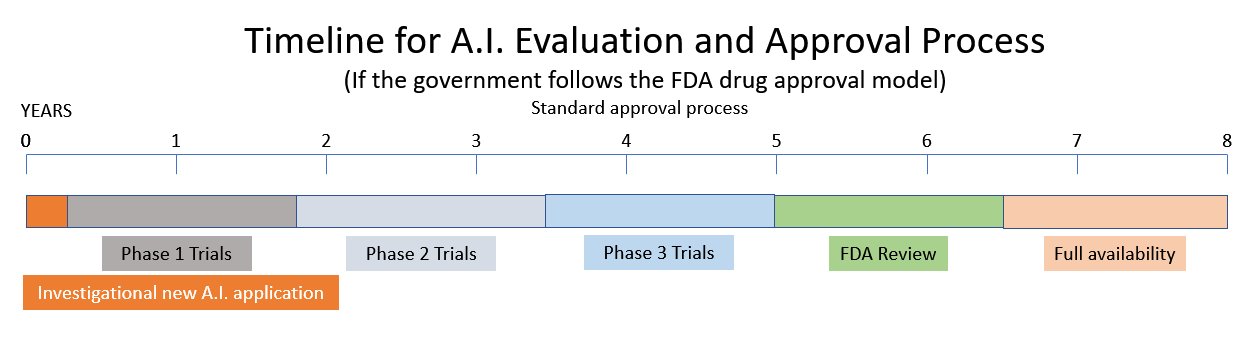
Ein neues Medikament auf den Markt zu bringen, dauert 10 – 15 Jahre und kostet eine halbe Milliarde Dollar. (Quelle.) Wenn sich die Regierung also dafür entscheidet, den Modellen des NRC und der FDA zu folgen, müssen Sie damit rechnen, dass der jüngste Tsunami aufregender Innovationen im Bereich der künstlichen Intelligenz in naher Zukunft durch staatliche Regulierung und Bürokratie ersetzt wird.






.jpg){kind=link}