AI: de doos van Pandora of innovatie
Een balans vinden tussen het oplossen van de nieuwe vragen die AI oproept en de voordelen van innovatie
Er zijn twee grote problemen met betrekking tot AI en intellectueel eigendom. Een daarvan is het gebruik van inhoud. De gebruiker voert inhoud in de vorm van een prompt in waarop de AI een actie uitvoert. Wat gebeurt er met die inhoud nadat AI reageert? De andere is het creëren van inhoud door AI. AI gebruikt zijn algoritmen en kennisbank van trainingsgegevens om te reageren op een prompt en output te genereren. Gezien het feit dat het is getraind op mogelijk auteursrechtelijk beschermd materiaal en ander intellectueel eigendom, is de uitvoer nieuw genoeg voor auteursrechten?
AI's gebruik van intellectueel eigendom
Het lijkt alsof AI en ChatGPT elke dag in het nieuws zijn. ChatGPT, of Generative Pre-trained Transformer, is een AI-chatbot die eind 2022 is gelanceerd door OpenAI. ChatGPT maakt gebruik van een AI-model dat via internet is getraind. Het non-profitbedrijf OpenAI biedt momenteel een gratis versie van ChatGPT aan, die ze de onderzoeksvoorbeeld. “De OpenAI API kan worden toegepast op vrijwel elke taak die betrekking heeft op het begrijpen of genereren van natuurlijke taal, code of afbeeldingen. “(bron). Naast het gebruik ChatGPT als open gesprek met en AI-assistent (of, Marv, een sarcastische chatbot die met tegenzin vragen beantwoordt), kan hij ook worden gebruikt om:
- Vertaal programmeertalen – Vertaal van de ene programmeertaal naar de andere.
- Leg code uit – Leg een gecompliceerd stuk code uit.
- Schrijf een Python-docstring – Schrijf een docstring voor een Python-functie.
- Bugs in Python-code oplossen - Zoek en repareer bugs in de broncode.
De snelle adoptie van AI
Softwarebedrijven worstelen om AI in hun applicaties te integreren. Er is een huisnijverheid rond ChatGPT. Sommigen maken applicaties die gebruikmaken van de API's. Er is zelfs één website die zichzelf factureert als een ChatGPT-promptmarktplaats. Ze verkopen ChatGPT-prompts!

Samsung was een bedrijf dat het potentieel zag en op de kar sprong. Een ingenieur bij Samsung gebruikte ChatGPT om hem te helpen met het debuggen van code en het oplossen van de fouten. Eigenlijk hebben ingenieurs bij drie verschillende gelegenheden bedrijfs-IP in de vorm van broncode geüpload naar OpenAI. Samsung stond toe - volgens sommige bronnen aangemoedigd - zijn ingenieurs in de halfgeleiderdivisie om ChatGPT te gebruiken om vertrouwelijke broncode te optimaliseren en te herstellen. Nadat dat spreekwoordelijke paard naar de wei was uitgenodigd, sloeg Samsung de schuurdeur dicht door de inhoud die met ChatGPT werd gedeeld te beperken tot minder dan een tweet en onderzoek te doen naar het personeel dat betrokken was bij het datalek. Het overweegt nu om een eigen chatbot te bouwen. (Afbeelding gegenereerd door ChatGPT - een mogelijk onbedoeld ironische, zo niet humoristische, reactie op de prompt, "een team van Samsung-software-ingenieurs gebruikt OpentAI ChatGPT om softwarecode te debuggen wanneer ze zich met verbazing en afgrijzen realiseren dat de tandpasta uit de tube is en ze hebben het intellectueel eigendom van het bedrijf aan het internet blootgesteld”.)
Het classificeren van de inbreuk op de beveiliging als een "lek" kan een verkeerde benaming zijn. Als je een kraan opendraait, is het geen lek. Op analoge wijze moet alle inhoud die u invoert in OpenAI als openbaar worden beschouwd. Dat is OPEN AI. Het heet niet voor niets open. Alle gegevens die u in ChatGpt invoert, kunnen worden gebruikt "om hun AI-services te verbeteren of kunnen door hen en / of zelfs hun gelieerde partners voor verschillende doeleinden worden gebruikt." (bron.) OpenAI waarschuwt gebruikers wel in zijn gebruiker gids: “We kunnen geen specifieke prompts uit uw geschiedenis verwijderen. Deel alstublieft geen gevoelige informatie in uw gesprekken”, voegt ChatGPT zelfs een voorbehoud toe reacties, "Houd er rekening mee dat de chatinterface bedoeld is als demonstratie en niet bedoeld is voor productiegebruik."
Samsung is niet het enige bedrijf dat eigen, persoonlijke en vertrouwelijke informatie vrijgeeft in het wild. Een onderzoek afstand ontdekte dat alles, van strategische bedrijfsdocumenten tot de namen van patiënten en medische diagnoses, in ChatGPT was geladen voor analyse of verwerking. Die gegevens worden door ChatGPT gebruikt om de AI-engine te trainen en de promptalgoritmen te verfijnen.
Gebruikers weten meestal niet hoe hun gevoelige persoonlijk identificeerbare informatie wordt beheerd, gebruikt, opgeslagen of zelfs gedeeld. Online bedreigingen en kwetsbaarheden in AI-chatten zijn belangrijke beveiligingsproblemen als een organisatie en haar systemen worden gecompromitteerd, de persoonlijke gegevens worden gelekt, gestolen en gebruikt voor kwaadaardige doeleinden.
De aard van AI-chatten is het verwerken en analyseren van een grote hoeveelheid gegevens, inclusief persoonlijke informatie, om relevante resultaten te produceren. Het gebruik van big data lijkt echter af te wijken van het begrip privacy…(bron.)
Dit is geen aanklacht tegen AI. Het is een herinnering. Het herinnert eraan dat AI moet worden behandeld als internet. Met andere woorden, beschouw alle informatie die u invoert in OpenAI als openbaar. (Onthoud ook dat alle output die door AI wordt gegenereerd, verder kan worden getransformeerd of als model kan worden gebruikt om antwoorden voor toekomstige gebruikers te genereren.) Het is een manier waarop AI intellectueel eigendom en privacy in gevaar brengt. Een andere controverse is het gebruik van auteursrechtelijk beschermd materiaal door AI.
AI en het copyright-dilemma
Er zijn een aantal zorgen met betrekking tot redelijk gebruik van AI en auteursrechtelijk beschermd materiaal. AI is in staat het geschreven woord te verwerken. Het kan samenvatten, analyseren, categoriseren en zelfs nieuwe inhoud creëren op basis van een bepaalde schrijfstijl. AI wordt getraind op inhoud. Ik denk dat het moeilijk voor hem zou zijn om te voorkomen dat hij auteursrechtelijk beschermd materiaal consumeert. Voor zover ik weet, behandelt de huidige wetgeving het gebruik van auteursrechtelijk beschermde inhoud voor training niet volledig. (Beeld)
Ik vroeg OpenAI om de tekst te typen voor de eerste pagina van "To Kill a Mockingbird" van Harper Lee. Het deed. Dus ik ben er vrij zeker van dat het toegang heeft tot de auteursrechtelijk beschermde tekst. Het kan dan een cv maken in de stijl van Harper Lee. Of u kunt het vragen om een sonnet te maken op basis van het thema van het boek.
| Een Shakespeariaans sonnet
Gebaseerd op het thema "To Kill a Mockingbird" In Maycomb's stad waar gerechtigheid een droom lijkt, Young Scout en Jem vinden een waarheid die hun leeftijd te boven gaat. Hun vader, Atticus, een nobel thema Wiens moreel kompas hen door hun angsten leidt. Tom Robinson, een zwarte man die vals beschuldigd wordt, Ontkende een stem, een proces dat rechtvaardig en eerlijk is. Maar Atticus verdedigt hem, niet geamuseerd, Want waarheid en gerechtigheid moeten onze zaak zijn. De spotlijster, een symbool van pure gratie, Onschuldig aan kwaad, brengt zijn lied vrede. Maar het kwaad schuilt in de ruimte van deze kleine stad, En rechtvaardigheid valt als de haat begint toe te nemen. Harper Lee's woorden, een waarschuwing voor ons allemaal, Om te vechten voor gerechtigheid, opdat het niet onze val wordt. |
|---|
Er is geen kans dat dit wordt verward met het werk van Shakespeare - of dat van Harper Lee trouwens. Het is transformationele nieuwe inhoud die duidelijk niet moet worden verward met het origineel. Er rijzen verschillende vragen. Op welk punt wordt het transformationeel? Met andere woorden, hoeveel moet het oorspronkelijke werk worden gewijzigd om als nieuwe inhoud te worden beschouwd?
Een andere vraag - en dit geldt evenzeer voor alle inhoud die door AI is gemaakt - wie is de eigenaar? Wie bezit het auteursrecht op de inhoud? Of kan het werk zelfs auteursrechtelijk beschermd zijn? Er kan een argument worden aangevoerd dat de eigenaar van het copyright de persoon moet zijn die de prompt heeft gemaakt en het verzoek heeft ingediend bij OpenAI. Er is een nieuwe huisnijverheid ontstaan rond snel schrijven. Op sommige online marktplaatsen kunt u tussen $ 2 en 20 betalen voor prompts waarmee u door de computer gegenereerde kunst of geschreven tekst kunt krijgen.
Anderen zeggen dat het van de ontwikkelaar van OpenAI zou moeten zijn. Dat roept nog meer vragen op. Hangt het af van het model of de engine die wordt gebruikt om de respons te genereren?
Ik denk dat het meest overtuigende argument dat kan worden aangevoerd, is dat op inhoud die door een computer is gegenereerd, geen auteursrecht kan rusten. Het US Copyright Office heeft een beleidsverklaring afgegeven in de Federaal register, maart 2023. Daarin staat: "Omdat het Bureau elk jaar ongeveer een half miljoen registratieaanvragen ontvangt, ziet het nieuwe trends in registratieactiviteit die mogelijk een wijziging of uitbreiding van de vereiste informatie over een aanvraag vereisen." Het vervolgt: “Deze technologieën, vaak omschreven als 'generatieve AI', roepen vragen op over de vraag of het materiaal dat ze produceren auteursrechtelijk beschermd is, of werken die bestaan uit zowel door mensen geschreven als door AI gegenereerd materiaal mogen worden geregistreerd, en wat informatie moet aan het Bureau worden verstrekt door aanvragers die ze willen inschrijven.”
"The Office" erkent dat er vragen zijn over het toepassen van een 150 jaar oude wet op technologie die zijn eerste verjaardag nog niet heeft meegemaakt. Om die vragen te beantwoorden, lanceerde het Copyright Office een initiatief om de kwestie te bestuderen. Het gaat onderzoek doen en openstaan voor publieke commentaar over hoe het het gebruik van auteursrechtelijk beschermde inhoud in de training van AI moet aanpakken, en hoe het de gegenereerde inhoud moet beschouwen.
De Federaal register, enigszins verrassend, biedt wat kleurcommentaar en beschrijft een aantal interessante gevallen die verband houden met het "auteurschap" van werken en het historische beleid inzake auteursrecht. Een zaak die werd berecht, was dat een aap geen auteursrecht kan hebben. In dit specifieke geval maakten apen beelden met een camera. De rechtbank oordeelde dat er geen auteursrecht op de afbeeldingen kon rusten omdat de Auteurswet verwijst naar de ''kinderen'', ''weduwe'', ''kleinkinderen'' en ''weduwnaar'' van een auteur. In de ogen van de rechtbank sloot deze taal apen uit. "De bestaande registratierichtlijnen van het Bureau vereisen al lang dat werken het product zijn van menselijk auteurschap."
Wanneer OpenAI wordt gevraagd naar de controverse, zegt het: “Ja, er zijn grijze gebieden van het intellectueel eigendomsrecht als het gaat om software en AI. Vanwege de complexiteit van de technologie en het ontbreken van gevestigde juridische precedenten, is het vaak moeilijk om te bepalen welke rechten een maker heeft op zijn werk. Als een AI-algoritme bijvoorbeeld is gebaseerd op een roman of een bestaand softwareprogramma, is het niet altijd duidelijk wie de rechten op het algoritme of het originele werk bezit. Bovendien is de reikwijdte van octrooibescherming voor AI-gerelateerde uitvindingen een omstreden juridische kwestie.”
OpenAI heeft hier gelijk in. Het is duidelijk dat een Amerikaanse aanvraag voor auteursrecht menselijk auteurschap moet hebben. Tussen nu en het einde van het jaar zal het Copyright Office proberen enkele van de resterende vragen op te lossen en aanvullende richtlijnen te geven.
Octrooirecht en AI
Discussies over het Amerikaanse octrooirecht en of het betrekking heeft op uitvindingen die door AI zijn gedaan, is een soortgelijk verhaal. Momenteel, zoals de wet schrijft, moeten octrooieerbare uitvindingen worden gedaan door natuurlijke personen. Het Amerikaanse Hooggerechtshof weigerde een zaak te behandelen die dat idee betwistte. (bron.) Net als het US Copyright Office evalueert het US Patent and Trademark Office zijn standpunt. Het is mogelijk dat de USPTO besluit om intellectueel eigendomsrecht complexer te maken. De makers, ontwikkelaars en eigenaren van AI kunnen eigenaar zijn van een deel van de uitvinding die het helpt creëren. Kan een niet-mens mede-eigenaar zijn?
De techgigant Google woog onlangs. "'Wij vinden dat AI volgens de Amerikaanse octrooiwet niet als uitvinder mag worden bestempeld, en vinden dat mensen patenten moeten hebben op innovaties die tot stand zijn gekomen met behulp van AI', zei Laura Sheridan, senior patent counsel bij Google." In de verklaring van Google beveelt het aan om meer training en bewustzijn van AI, de tools, de risico's en best practices voor octrooi-onderzoekers te geven. (bron.) Waarom past het Octrooibureau het gebruik van AI niet toe om AI te evalueren?
AI en de toekomst
De mogelijkheden van AI en in feite het hele AI-landschap zijn in de afgelopen 12 maanden veranderd. Veel bedrijven willen de kracht van AI benutten en profiteren van de voorgestelde voordelen van snellere en goedkopere code en inhoud. Zowel het bedrijfsleven als de wet moeten een beter begrip hebben van de implicaties van de technologie met betrekking tot privacy, intellectueel eigendom, patenten en copyright. (Afbeelding gegenereerd door ChatGPT met menselijke prompt "AI en de toekomst". Let op, afbeelding is niet auteursrechtelijk beschermd).
Update: 17 mei 2023
Er zijn elke dag ontwikkelingen op het gebied van AI en de wet. De Senaat heeft een subcommissie voor de rechterlijke macht voor privacy, technologie en recht. Het houdt een reeks hoorzittingen over Oversight of AI: Rule for Artificial Intelligence. Het is van plan "de regels van AI te schrijven". Met als doel "die nieuwe technologieën te demystificeren en verantwoordelijk te houden om enkele van de fouten uit het verleden te vermijden", zegt senator Richard Blumenthal, voorzitter van de subcommissie. Interessant is dat hij om de vergadering te openen een diepe nep-audio afspeelde die zijn stem kloonde met ChatGPT-inhoud die was getraind op zijn eerdere opmerkingen:
Te vaak hebben we gezien wat er gebeurt als technologie sneller gaat dan regelgeving. De ongebreidelde exploitatie van persoonsgegevens, de verspreiding van desinformatie en de verdieping van maatschappelijke ongelijkheden. We hebben gezien hoe algoritmische vooroordelen discriminatie en vooroordelen in stand kunnen houden en hoe het gebrek aan transparantie het vertrouwen van het publiek kan ondermijnen. Dit is niet de toekomst die we willen.
Het overweegt een aanbeveling om een nieuwe regelgevende instantie voor kunstmatige intelligentie op te richten op basis van de modellen van de Food and Drug Administration (FDA) en de Nuclear Regulatory Commission (NRC). (bron.) Een van de getuigen voor de AI-subcommissie suggereerde dat AI een licentie zou moeten krijgen op dezelfde manier als farmaceutica worden gereguleerd door de FDA. Andere getuigen beschrijven de huidige staat van AI als het Wilde Westen met gevaren van vooringenomenheid, weinig privacy en beveiligingsproblemen. Ze beschrijven een West-Werelddystopie van machines die "krachtig, roekeloos en moeilijk te controleren" zijn.
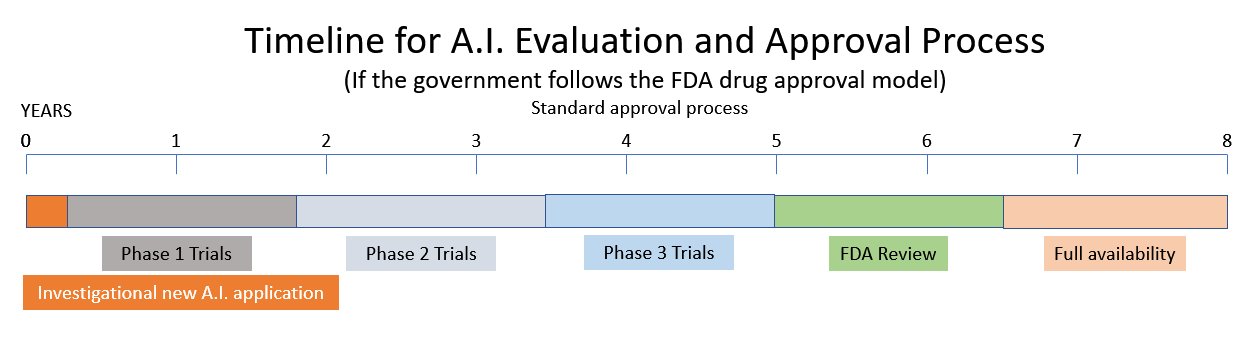
Een nieuw medicijn op de markt brengen duurt 10 tot 15 jaar en een half miljard dollar. (bron.) Dus als de regering besluit de modellen van de NRC en de FDA te volgen, kijk dan uit naar de recente tsunami van opwindende innovatie op het gebied van kunstmatige intelligentie die in de zeer nabije toekomst zal worden vervangen door overheidsregulering en bureaucratie.






.jpg){kind=link}