AI: Pandoras box eller innovation
Att hitta en balans mellan att lösa de nya frågorna AI väcker och fördelarna med innovation
Det finns två enorma frågor relaterade till AI och immateriella rättigheter. En är dess användning av innehåll. Användaren anger innehåll i form av en prompt där AI:n utför någon åtgärd. Vad händer med innehållet efter att AI svarar? Den andra är AI:s skapande av innehåll. AI använder sina algoritmer och kunskapsbas för träningsdata för att svara på en uppmaning och generera utdata. Med tanke på det faktum att den har utbildats i potentiellt upphovsrättsskyddat material och annan immateriell egendom, räcker den utgående romanen till upphovsrätt?
AI:s användning av immateriella rättigheter
Det verkar som om AI och ChatGPT är i nyheterna varje dag. ChatGPT, eller Generative Pre-trained Transformer, är en AI-chatbot som lanserades sent 2022 av OpenAI. ChatGPT använder en AI-modell som har tränats med hjälp av internet. Det ideella företaget, OpenAI, erbjuder för närvarande en gratisversion av ChatGPT som de kallar förhandsgranskning av forskning. "OpenAI API kan appliceras på praktiskt taget alla uppgifter som involverar förståelse eller generering av naturligt språk, kod eller bilder. "(Källa). Förutom att använda ChatGPT som ett öppet samtal med en AI-assistent (eller, Marv, en sarkastisk chattbot som motvilligt svarar på frågor), kan den också användas för att:
- Översätt programmeringsspråk – Översätt från ett programmeringsspråk till ett annat.
- Förklara kod – Förklara en komplicerad kod.
- Skriv en Python-docstring – Skriv en docstring för en Python-funktion.
- Fixa buggar i Python-kod – Hitta och fixa buggar i källkoden.
Det snabba antagandet av AI
Mjukvaruföretag försöker integrera AI i sina applikationer. Det finns en stugindustri runt ChatGPT. Vissa skapar applikationer som utnyttjar dess API:er. Det finns till och med en webbplats som fakturerar sig själv som en ChatGPT-promptmarknadsplats. De säljer ChatGPT-uppmaningar!

Samsung var ett företag som såg potentialen och hoppade på tåget. En ingenjör på Samsung använde ChatGPT för att hjälpa honom att felsöka kod och hjälpa honom att fixa felen. Egentligen laddade ingenjörer vid tre olika tillfällen upp företagets IP i form av källkod till OpenAI. Samsung tillät – uppmuntrade vissa källor – sina ingenjörer inom halvledardivisionen att använda ChatGPT för att optimera och fixa konfidentiell källkod. Efter att den ökända hästen bjöds ut på bete, slog Samsung igen ladugårdsdörren genom att begränsa innehåll som delas med ChatGPT till mindre än en tweet och undersöka personalen som var involverad i dataläckan. Den överväger nu att bygga sin egen chatbot. (Bild genererad av ChatGPT – ett potentiellt oavsiktligt ironiskt, om inte humoristiskt, svar på uppmaningen, ”ett team av Samsungs mjukvaruingenjörer som använder OpentAI ChatGPT för att felsöka programvarukod när de med förvåning och fasa inser att tandkrämen är ute ur tuben och de har exponerat företagens immateriella rättigheter för internet”.)
Att klassificera säkerhetsöverträdelsen som en "läcka" kan vara en felaktig benämning. Om du slår på en kran är det inte en läcka. Analogt bör allt innehåll du anger i OpenAI betraktas som offentligt. Det är OPEN AI. Det kallas öppet av en anledning. All data du anger i ChatGpt kan användas "för att förbättra deras AI-tjänster eller kan användas av dem och/eller till och med deras allierade partners för en mängd olika ändamål." (Källa.) OpenAI varnar användare i sin användare styra: "Vi kan inte ta bort specifika uppmaningar från din historik. Vänligen dela inte någon känslig information i dina konversationer,” ChatGPT inkluderar till och med en varning i sin svar, "observera att chattgränssnittet är tänkt som en demonstration och inte är avsett för produktionsanvändning."
Samsung är inte det enda företaget som släpper proprietär, personlig och konfidentiell information i naturen. En forskning företag fann att allt från företagets strategiska dokument till patientens namn och medicinska diagnoser hade laddats in i ChatGPT för analys eller bearbetning. Dessa data används av ChatGPT för att träna AI-motorn och för att förfina promptalgoritmerna.
Användare vet oftast inte hur deras känsliga personliga identifieringsinformation hanteras, används, lagras eller till och med delas. Onlinehot och sårbarheter i AI-chatt är betydande säkerhetsproblem om en organisation och dess system äventyras, personuppgifterna läcker, stjäls och används i skadliga syften.
Arten av AI-chatt är att bearbeta och analysera en stor mängd data, inklusive personlig information, för att producera relevanta resultat. Användningen av big data verkar dock skilja sig från begreppet integritet...(Källa.)
Detta är inte ett åtal mot AI. Det är en påminnelse. Det är en påminnelse om att AI bör behandlas som internet. Med andra ord, betrakta all information du matar in i OpenAI som offentlig. (Kom också ihåg att alla utdata som genereras av AI kan transformeras ytterligare eller användas som en modell för att generera svar för framtida användare.) Det är ett sätt på vilket AI äventyrar immateriella rättigheter och integritet. En annan kontrovers är AI:s användning av upphovsrättsskyddat material.
AI och upphovsrättsdilemmat
Det finns ett antal problem relaterade till AI fair use och upphovsrättsskyddat material. AI kan bearbeta det skrivna ordet. Den kan sammanfatta, analysera, kategorisera och till och med skapa nytt innehåll baserat på en viss skrivstil. AI tränas på innehåll. Jag tror att det skulle vara svårt för det att undvika att konsumera upphovsrättsskyddat material. Såvitt jag vet tar gällande lag inte helt upp användningen av upphovsrättsskyddat innehåll för utbildning. (Bild)
Jag bad OpenAI att skriva texten för första sidan av "To Kill a Mockingbird" av Harper Lee. Det gjorde. Så jag är ganska säker på att den har tillgång till den upphovsrättsskyddade texten. Det kan sedan skapa ett CV i stil med Harper Lee. Eller så kan du be den att skapa en sonett baserat på bokens tema.
| En Shakespeares sonett
Baserat på temat "To Kill a Mockingbird" I Maycombs stad där rättvisa verkar vara en dröm, Young Scout och Jem hittar sanning bortom sina år. Deras far, Atticus, ett ädelt tema Vars moraliska kompass vägleder dem genom deras rädsla. Tom Robinson, en svart man falskt anklagad, Nekat en röst, en rättegång som är rättvis och rättvis. Men Atticus försvarar honom, inte road, För sanning och rättvisa måste vara vår angelägenhet. Mockingbirden, en symbol för ren nåd, Oskyldig till skada ger dess sång fred. Men ondskan lurar i den här lilla stadens utrymme, Och rättvisan faller när hatet börjar öka. Harper Lees ord, en varning till oss alla, Att kämpa för rättvisa, så att det inte blir vårt fall. |
|---|
Det finns ingen chans att detta kommer att förväxlas med Shakespeares verk – eller Harper Lees för den delen. Det är ett omvandlande nytt innehåll som uppenbarligen inte ska förväxlas med originalet. Flera frågor uppstår. När blir det transformerande? Med andra ord, hur mycket behöver originalverket ändras för att det ska betraktas som nytt innehåll?
En annan fråga – och detta gäller lika mycket för allt innehåll skapat av AI – vem äger det? Vem äger upphovsrätten till innehållet? Eller kan verket ens vara upphovsrättsskyddat? Ett argument kan framföras att ägaren av upphovsrätten bör vara den person som skapade uppmaningen och gjorde begäran från OpenAI. Det finns en ny stugindustri kring snabb författarskap. På vissa onlinemarknadsplatser kan du betala mellan $2 och 20 för uppmaningar som ger dig datorgenererad konst eller skriven text.
Andra säger att det borde tillhöra utvecklaren av OpenAI. Det väcker ännu fler frågor. Beror det på modellen eller motorn som används för att generera svaret?
Jag tror att det mest övertygande argumentet att framföra är att innehåll som genereras av en dator inte kan vara upphovsrättsskyddat. US Copyright Office utfärdade en policyförklaring i Federal Register, mars 2023. I det står det, "Eftersom kontoret tar emot ungefär en halv miljon ansökningar om registrering varje år, ser det nya trender i registreringsaktivitet som kan kräva att den information som krävs för att avslöjas i en ansökan ändras eller utökas." Den fortsätter med att säga: "Dessa tekniker, som ofta beskrivs som 'generativ AI', väcker frågor om huruvida materialet de producerar är skyddat av upphovsrätt, om verk som består av både mänskligt författat och AI-genererat material kan registreras och vad information bör lämnas till byrån av sökande som vill registrera dem.”
"The Office" erkänner att det finns frågor relaterade till att tillämpa en 150 år gammal lag på teknik som inte har sett sin första födelsedag. För att ta itu med dessa frågor lanserade Copyright Office ett initiativ för att studera frågan. Den kommer att undersöka och vara öppen för offentliga kommentarer om hur den bör ta itu med användningen av upphovsrättsskyddat innehåll i utbildningen av AI, såväl som hur den bör beakta innehållet som genereras.
Smakämnen Federalt register, något överraskande, ger lite färgkommentarer och beskriver ett antal intressanta fall relaterade till "författarskap" av verk och dess historiska policy om upphovsrätt. Ett fall som avgjordes menade att en apa inte kan inneha upphovsrätt. I det här specifika fallet tog apor bilder med en kamera. Domstolen beslutade att bilderna inte kunde vara upphovsrättsskyddade eftersom upphovsrättslagen hänvisar till en författares "barn", "änka", "barnbarn" och "änkling". I domstolens ögon uteslöt detta språk apor. "Kontorets befintliga registreringsvägledning har länge krävt att verk är en produkt av mänskligt författarskap."
När OpenAI tillfrågas om kontroversen står det: "Ja, det finns gråzoner inom immaterialrätt när det kommer till mjukvara och AI. På grund av teknikens komplexitet och avsaknaden av etablerade juridiska prejudikat är det ofta svårt att avgöra vilka rättigheter en kreatör har till sitt verk. Till exempel, om en AI-algoritm är baserad på en roman eller ett befintligt program, är det inte alltid klart vem som äger rättigheterna till algoritmen eller originalverket. Dessutom är omfattningen av patentskyddet för AI-relaterade uppfinningar en omtvistad juridisk fråga."
OpenAI har rätt i detta. Det är tydligt att en amerikansk ansökan om upphovsrätt måste ha mänskligt författarskap. Mellan nu och slutet av året kommer Copyright Office att försöka reda ut några av de återstående frågorna och ge ytterligare vägledning.
Patenträtt och AI
Diskussioner kring amerikansk patentlagstiftning och om den täcker uppfinningar gjorda av AI är en liknande historia. För närvarande, som lagen är skriven, måste patenterbara uppfinningar göras av fysiska personer. USA:s högsta domstol vägrade att höra ett fall som ifrågasatte den uppfattningen. (Källa.) Liksom US Copyright Office utvärderar US Patent and Trademark Office sin position. Det är möjligt att USPTO beslutar sig för att göra immateriell egendom mer komplex. AI-skaparna, utvecklarna, ägarna kan äga en del av uppfinningen som den hjälper till att skapa. Kan en icke-människa vara delägare?
Teknikjätten Google vägde in nyligen. "Vi anser att AI inte bör märkas som en uppfinnare enligt USA:s patentlag, och anser att människor bör ha patent på innovationer som åstadkommits med hjälp av AI," sa Laura Sheridan, senior patentrådgivare på Google. I Googles uttalande rekommenderar den ökad utbildning och medvetenhet om AI, verktygen, riskerna och bästa praxis för patentgranskare. (Källa.) Varför använder inte patentverket användningen av AI för att utvärdera AI?
AI och framtiden
Förmågan hos AI och faktiskt hela AI-landskapet har förändrats på bara de senaste 12 månaderna, eller så. Många företag vill utnyttja kraften i AI och skörda de föreslagna fördelarna med snabbare och billigare kod och innehåll. Både företag och juridik behöver ha en bättre förståelse för implikationerna av tekniken när den relaterar till integritet, immateriella rättigheter, patent och upphovsrätt. (Bild genererad av ChatGPT med mänsklig prompt "AI and the Future". Observera att bilden inte är upphovsrättsskyddad).
Uppdatering: 17 maj 2023
Det fortsätter att ske utvecklingar relaterat till AI och juridik varje dag. Senaten har en underkommitté för rättsväsendet för integritet, teknik och lag. Den håller en serie utfrågningar om Oversight of AI: Rule for Artificial Intelligence. Den har för avsikt att "skriva reglerna för AI." Med målet "att avmystifiera och hålla ansvariga dessa nya teknologier för att undvika några av det förflutnas misstag", säger ordföranden för underkommittén, senator Richard Blumenthal. Intressant nog, för att öppna mötet, spelade han ett djupt falskt ljud som klonade sin röst med ChatGPT-innehåll tränat på hans tidigare kommentarer:
Alltför ofta har vi sett vad som händer när tekniken överträffar regleringen. Det ohämmade utnyttjandet av personuppgifter, spridningen av desinformation och fördjupningen av samhälleliga ojämlikheter. Vi har sett hur algoritmiska fördomar kan vidmakthålla diskriminering och fördomar och hur bristen på transparens kan undergräva allmänhetens förtroende. Det här är inte framtiden vi vill ha.
Den överväger en rekommendation att skapa en ny tillsynsmyndighet för artificiell intelligens baserat på modellerna från Food and Drug Administration (FDA) och Nuclear Regulatory Commission (NRC). (Källa.) Ett av vittnena inför AI-underkommittén föreslog att AI skulle licensieras på samma sätt som läkemedel regleras av FDA. Andra vittnen beskriver det nuvarande tillståndet för AI som vilda västern med faror för partiskhet, lite integritet och säkerhetsproblem. De beskriver en dystopi i västvärlden av maskiner som är "kraftfulla, hänsynslösa och svåra att kontrollera."
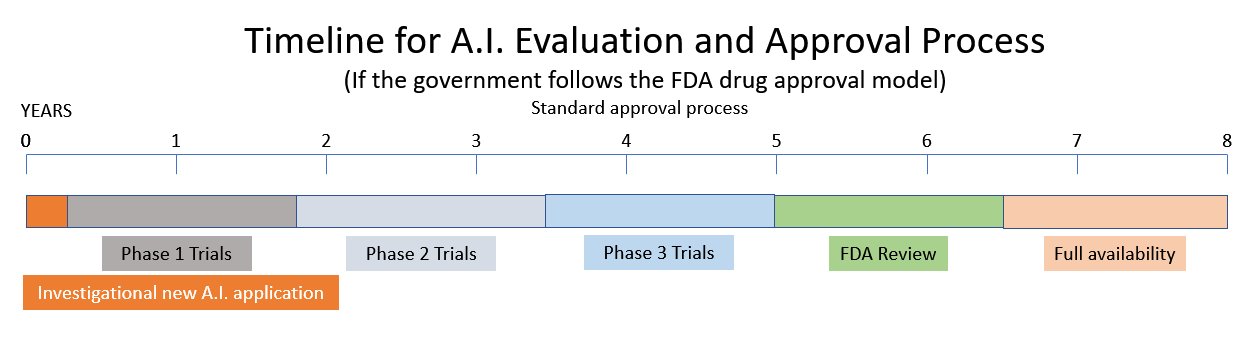
Att få ut ett nytt läkemedel på marknaden tar 10 – 15 år och en halv miljard dollar. (Källa.) Så om regeringen beslutar sig för att följa NRC:s och FDA:s modeller, leta efter den senaste tsunamin av spännande innovationer inom området för artificiell intelligens som inom en mycket snar framtid kommer att ersättas av statlig reglering och byråkrati.






.jpg){kind=link}