AI: Pandořina skříňka nebo inovace
Hledání rovnováhy mezi řešením nových otázek, které AI vyvolává, a výhodami inovací
S umělou inteligencí a duševním vlastnictvím souvisí dva obrovské problémy. Jedním z nich je použití obsahu. Uživatel zadá obsah ve formě výzvy, na které AI provede nějakou akci. Co se stane s tímto obsahem poté, co AI zareaguje? Druhým je vytváření obsahu AI. Umělá inteligence využívá své algoritmy a znalostní základnu trénovacích dat, aby reagovala na výzvu a generovala výstup. S ohledem na skutečnost, že byl trénován na potenciálně chráněný materiál a další duševní vlastnictví, je výstup dostatečně nový, aby se týkal autorských práv?
AI využívá duševní vlastnictví
Zdá se, že AI a ChatGPT jsou ve zprávách každý den. ChatGPT, neboli Generative Pre-trained Transformer, je AI chatbot spuštěný koncem roku 2022 OpenAI. ChatGPT používá model umělé inteligence, který byl trénován pomocí internetu. Nezisková společnost OpenAI v současné době nabízí bezplatnou verzi ChatGPT, kterou nazývají náhled výzkumu. „OpenAI API lze použít prakticky na jakýkoli úkol, který zahrnuje porozumění nebo generování přirozeného jazyka, kódu nebo obrázků. “ (Zdroj). Kromě používání ChatGPT jako otevřený rozhovor s asistentem AI (nebo, Marv, sarkastický chatovací robot, který neochotně odpovídá na otázky), lze jej také použít k:
- Překlad programovacích jazyků – Překlad z jednoho programovacího jazyka do druhého.
- Vysvětlete kód – Vysvětlete komplikovaný kus kódu.
- Napište dokumentační řetězec Pythonu – Napište dokumentační řetězec pro funkci Pythonu.
- Opravte chyby v kódu Pythonu – Najděte a opravte chyby ve zdrojovém kódu.
Rychlé přijetí AI
Softwarové společnosti se snaží integrovat AI do svých aplikací. Kolem ChatGPT existuje domácký průmysl. Někteří vytvářejí aplikace, které využívají jejich API. Existuje dokonce jeden web, který se účtuje jako a Rychlý trh ChatGPT. Prodávají výzvy ChatGPT!

Samsung byla jedna společnost, která viděla potenciál a skočila do rozjetého vlaku. Inženýr společnosti Samsung použil ChatGPT, aby mu pomohl odladit nějaký kód a pomohl mu opravit chyby. Ve skutečnosti inženýři při třech různých příležitostech nahráli firemní IP ve formě zdrojového kódu do OpenAI. Samsung dovolil – některé zdroje to uvádějí, povzbuzovaly – svým inženýrům v divizi polovodičů používat ChatGPT k optimalizaci a opravě důvěrného zdrojového kódu. Poté, co byl tento pověstný kůň pozván na pastvu, Samsung zabouchl dveře stodoly tím, že omezil obsah sdílený s ChatGPT na méně než tweet a prošetřil zaměstnance, kteří se podíleli na úniku dat. Nyní zvažuje vybudování vlastního chatbota. (Obrázek generovaný ChatGPT – potenciálně neúmyslně ironická, ne-li vtipná, odpověď na výzvu, „tým softwarových inženýrů Samsung, kteří používají OpentAI ChatGPT k ladění softwarového kódu, když si s překvapením a hrůzou uvědomí, že zubní pasta vytekla z tuby a vystavili podnikové duševní vlastnictví internetu.”)
Klasifikace narušení bezpečnosti jako „únik“ může být nesprávné označení. Pokud otevřeš kohoutek, není to únik. Podobně by měl být jakýkoli obsah, který zadáte do OpenAI, považován za veřejný. To je OPEN AI. Z nějakého důvodu se tomu říká otevřené. Jakákoli data, která zadáte do ChatGpt, mohou být použita „k vylepšení jejich služeb AI nebo mohou být použita jimi a/nebo dokonce jejich spřízněnými partnery pro různé účely“. (Zdroj.) OpenAI varuje uživatele ve svém uživateli průvodce: „Nejsme schopni odstranit konkrétní výzvy z vaší historie. Prosím, nesdílejte ve svých konverzacích žádné citlivé informace,“ ChatGPT dokonce obsahuje upozornění odpovědi"Upozorňujeme, že rozhraní chatu je zamýšleno jako ukázka a není určeno pro produkční použití."
Samsung není jedinou společností, která uvolňuje proprietární, osobní a důvěrné informace do volné přírody. Výzkum společnost zjistili, že vše od podnikových strategických dokumentů po jména pacientů a lékařskou diagnózu bylo nahráno do ChatGPT za účelem analýzy nebo zpracování. Tato data používá ChatGPT k trénování AI motoru a ke zpřesnění rychlých algoritmů.
Uživatelé většinou nevědí, jak jsou jejich citlivé osobní identifikační údaje spravovány, používány, ukládány nebo dokonce sdíleny. Online hrozby a zranitelnosti v chatování s umělou inteligencí jsou významnými bezpečnostními problémy, pokud dojde ke kompromitaci organizace a jejích systémů, k úniku, odcizení a použití osobních údajů ke škodlivým účelům.
Povahou chatování s umělou inteligencí je zpracovávat a analyzovat velké množství dat, včetně osobních informací, za účelem získání relevantních výsledků. Zdá se však, že použití velkých dat se rozchází s konceptem soukromí…(Zdroj.)
Toto není obvinění z AI. Je to připomínka. Je to připomínka, že s umělou inteligencí by se mělo zacházet jako s internetem. Jinými slovy, považujte všechny informace, které vložíte do OpenAI, za veřejné. (Pamatujte také, že jakýkoli výstup generovaný umělou inteligencí lze dále transformovat nebo použít jako model pro generování odpovědí pro budoucí uživatele.) Je to jeden ze způsobů, jak umělá inteligence narušuje duševní vlastnictví a soukromí. Další kontroverzí je používání materiálu chráněného autorskými právy ze strany AI.
AI a dilema autorských práv
Existuje řada obav souvisejících s AI fair use a materiálem chráněným autorským právem. AI je schopna zpracovat psané slovo. Dokáže shrnout, analyzovat, kategorizovat a dokonce vytvořit nový obsah založený na konkrétním stylu psaní. Umělá inteligence je trénována na obsah. Myslím, že by pro ni bylo těžké vyhnout se konzumaci materiálu chráněného autorským právem. Pokud vím, současný zákon plně neřeší použití obsahu chráněného autorským právem pro školení. (Obraz)
Požádal jsem OpenAI, aby napsalo text pro první stránku „To Kill a Mockingbird“ od Harper Lee. Stalo se. Takže jsem si docela jistý, že má přístup k textu chráněnému autorským právem. Může pak vytvořit životopis ve stylu Harper Lee. Nebo jej můžete požádat, aby vytvořil sonet na téma knihy.
| Shakespearovský sonet
Na motivy „Zabít mockingbird“ Ve městě Maycomb, kde se spravedlnost zdá být snem, Mladý Scout a Jem nacházejí pravdu, která přesahuje jejich roky. Jejich otec Atticus, vznešené téma Jehož morální kompas je vede přes jejich strachy. Tom Robinson, černoch falešně obviněný, Odepřen hlas, soud, který je spravedlivý a spravedlivý. Ale Atticus ho brání, nepobaví se, Neboť pravda a spravedlnost musí být naší věcí. Posměváček, symbol čisté milosti, Nevinný, jeho píseň přináší mír. Ale zlo se skrývá v prostoru tohoto malého města, A spravedlnost padá, protože nenávist začíná narůstat. Slova Harper Lee, varování pro nás všechny, Bojovat za spravedlnost, aby to nebyl náš pád. |
|---|
Není šance, že si to splete se Shakespearovým dílem – nebo s dílem Harper Lee. Je zřejmé, že jde o transformační nový obsah, který nelze zaměňovat s původním. Nabízí se několik otázek. V jakém bodě se stává transformačním? Jinými slovy, jak moc je třeba původní dílo změnit, aby bylo považováno za nový obsah?
Další otázka – a to platí stejně pro jakýkoli obsah vytvořený AI – kdo jej vlastní? Kdo vlastní autorská práva k obsahu? Nebo může být dílo dokonce chráněno autorským právem? Lze argumentovat tím, že vlastníkem autorských práv by měla být osoba, která vytvořila výzvu a podala požadavek OpenAI. Kolem rychlého vytváření je nový domácký průmysl. Na některých online tržištích můžete zaplatit mezi 2 a 20 dolary za výzvy, které vám přinesou počítačem generované umění nebo psaný text.
Jiní říkají, že by měl patřit vývojáři OpenAI. To vyvolává ještě další otázky. Závisí to na modelu nebo motoru, který se používá ke generování odezvy?
Myslím, že nejpřesvědčivějším argumentem je, že obsah generovaný počítačem nemůže být chráněn autorským právem. Americký úřad pro autorská práva vydal prohlášení o zásadách v Federální rejstřík, březen 2023. V něm uvádí: „Protože úřad dostává každý rok zhruba půl milionu žádostí o registraci, vidí nové trendy v registrační činnosti, které mohou vyžadovat úpravu nebo rozšíření informací, které je třeba na žádosti uvádět. Dále říká: „Tyto technologie, často popisované jako ‚generativní umělá inteligence‘, vyvolávají otázky, zda je materiál, který produkují, chráněn autorským právem, zda lze registrovat díla sestávající z materiálu vytvořeného lidmi i vytvořeného umělou inteligencí a jaké informace by měli úřadu poskytnout žadatelé o jejich registraci.“
„Úřad“ uznává, že existují otázky související s aplikací 150 let starého zákona na technologii, která nezažila své první narozeniny. K vyřešení těchto otázek zahájil Úřad pro autorská práva iniciativu ke studiu tohoto problému. Chystá se prozkoumat a otevřít veřejným připomínkám, jak by měla řešit používání obsahu chráněného autorskými právy při školení AI, a také to, jak by měla posuzovat obsah, který je generován.
Projekt federální rejstřík, poněkud překvapivě nabízí barevný komentář a popisuje řadu zajímavých případů souvisejících s „autorstvím“ děl a jeho historickou politikou v oblasti autorských práv. Jeden případ, který byl souzený, rozhodl, že opice nemůže vlastnit autorská práva. V tomto konkrétním případě opice pořizovaly snímky fotoaparátem. Soud rozhodl, že obrázky nemohou být chráněny autorským právem, protože autorský zákon odkazuje na autorovy „děti“, „vdova“, „vnoučata“ a „vdovec“. V očích soudu tento jazyk opice vylučoval. "Stávající pokyny úřadu k registraci již dlouho vyžadují, aby díla byla produktem lidského autorství."
Když je OpenAI dotázána na kontroverzi, odpovídá: „Ano, existují šedé oblasti práva duševního vlastnictví, pokud jde o software a AI. Kvůli složitosti technologie a nedostatku zavedených právních precedentů je často obtížné určit, jaká práva má tvůrce ke svému dílu. Pokud je například algoritmus umělé inteligence založen na novém nebo existujícím softwarovém programu, není vždy jasné, kdo vlastní práva na algoritmus nebo původní dílo. Rozsah patentové ochrany pro vynálezy související s AI je navíc spornou právní otázkou.“
OpenAI má v tomto pravdu. Je jasné, že americká žádost o autorská práva musí mít lidské autorství. Do konce roku se Úřad pro autorská práva pokusí vyřešit některé zbývající otázky a poskytnout další pokyny.
Patentové právo a AI
Diskuse o patentovém právu USA a o tom, zda se vztahuje na vynálezy vytvořené umělou inteligencí, jsou podobný příběh. V současné době, jak je psán zákon, musí patentovatelné vynálezy vytvářet fyzické osoby. Nejvyšší soud USA odmítl projednat případ, který tuto myšlenku zpochybňoval. (Zdroj.) Stejně jako US Copyright Office i US Patent and Trademark Office vyhodnocuje svou pozici. Je možné, že se USPTO rozhodne zkomplikovat vlastnictví duševního vlastnictví. Tvůrci AI, vývojáři, vlastníci mohou vlastnit část vynálezu, který pomáhá vytvořit. Mohl by být částečným vlastníkem nečlověk?
Technologický gigant Google se nedávno zabýval. „Věříme, že umělá inteligence by podle amerického patentového zákona neměla být označena za vynálezce a věříme, že lidé by měli mít patenty na inovace vytvořené s pomocí umělé inteligence,“ řekla Laura Sheridan, senior patentová poradkyně společnosti Google. Google ve svém prohlášení doporučuje zvýšené školení a povědomí o AI, nástrojích, rizicích a osvědčených postupech pro patentové zkoušející. (Zdroj.) Proč Patentový úřad nepřijme použití AI k hodnocení AI?
AI a budoucnost
Schopnosti umělé inteligence a vlastně celé prostředí umělé inteligence se změnilo jen za posledních zhruba 12 měsíců. Mnoho společností chce využít sílu AI a využít navrhované výhody rychlejšího a levnějšího kódu a obsahu. Jak podniky, tak právo musí lépe rozumět důsledkům technologie, pokud jde o soukromí, duševní vlastnictví, patenty a autorská práva. (Obrázek generovaný ChatGPT s lidskou výzvou „AI a budoucnost“. Poznámka, obrázek není chráněn autorským právem).
Aktualizace: 17. května 2023
Každý den i nadále dochází k vývoji v oblasti umělé inteligence a práva. Senát má soudní podvýbor pro soukromí, technologie a právo. Pořádá sérii slyšení na téma Oversight of AI: Rule for Artificial Intelligence. Má v úmyslu „sepsat pravidla AI“. S cílem „demystifikovat a pohnat tyto nové technologie k odpovědnosti, abychom se vyhnuli některým chybám z minulosti,“ říká předseda podvýboru, senátor Richard Blumenthal. Zajímavé je, že k zahájení schůzky pustil hluboký falešný zvuk klonující svůj hlas pomocí obsahu ChatGPT trénovaného na jeho předchozích poznámkách:
Příliš často jsme byli svědky toho, co se stane, když technologie předstihnou regulaci. Bezuzdné využívání osobních údajů, šíření dezinformací a prohlubování společenských nerovností. Viděli jsme, jak mohou algoritmické předsudky udržovat diskriminaci a předsudky a jak nedostatek transparentnosti může podkopávat důvěru veřejnosti. Tohle není budoucnost, kterou chceme.
Zvažuje doporučení vytvořit novou agenturu pro regulaci umělé inteligence na základě modelů Food and Drug Administration (FDA) a Nuclear Regulatory Commission (NRC). (Zdroj.) Jeden ze svědků před podvýborem pro AI navrhl, že AI by měla být licencována podobně, jako jsou léčiva regulována FDA. Jiní svědci popisují současný stav AI jako Divoký západ s nebezpečím zaujatosti, malým soukromím a bezpečnostními problémy. Popisují dystopii západního světa strojů, které jsou „výkonné, bezohledné a obtížně ovladatelné“.
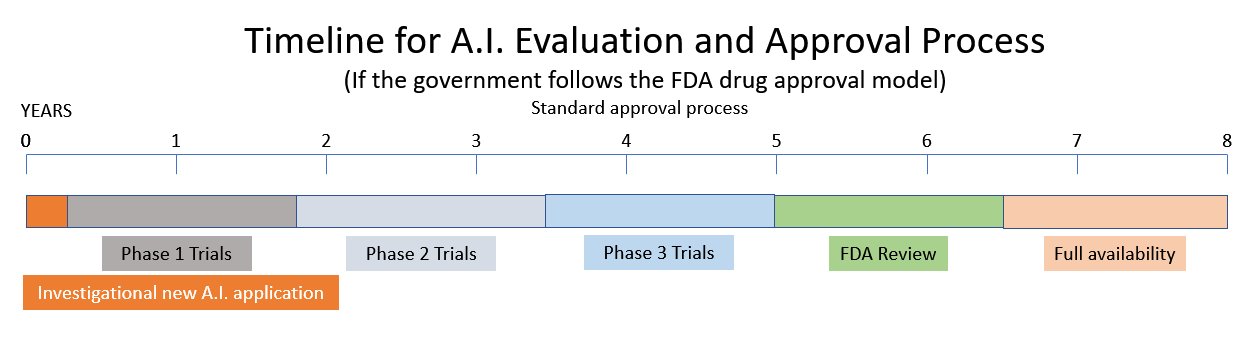
Uvedení nového léku na trh trvá 10 – 15 let a půl miliardy dolarů. (Zdroj.) Pokud se tedy vláda rozhodne následovat modely NRC a FDA, hledejte, že nedávné tsunami vzrušujících inovací v oblasti umělé inteligence bude ve velmi blízké budoucnosti nahrazeno vládními nařízeními a byrokracií.






.jpg){kind=link}