有两个与人工智能和知识产权相关的巨大问题。 一是内容的使用。 用户以提示的形式输入内容,AI 会根据提示执行某些操作。 AI 响应后该内容会怎样? 另一个是AI对内容的创造。 人工智能使用其算法和训练数据知识库来响应提示并生成输出。 考虑到它已经接受过潜在版权材料和其他知识产权的培训,输出的小说是否足以获得版权?
人工智能对知识产权的使用
AI 和 ChatGPT 似乎每天都出现在新闻中。 ChatGPT,即生成式预训练变压器,是 2022 年底推出的 AI 聊天机器人 OpenAI. ChatGPT 使用经过互联网训练的 AI 模型。 非营利性公司 OpenAI 目前提供免费版本的 ChatGPT,他们称之为 研究预览。 “OpenAI API 几乎可以应用于任何涉及理解或生成自然语言、代码或图像的任务。 “(来源). 除了使用 ChatGPT 作为与 AI 助手(或者, 马福,一个勉强回答问题的讽刺聊天机器人),它还可以用于:
- 翻译编程语言——从一种编程语言翻译成另一种。
- 解释代码——解释一段复杂的代码。
- 编写 Python 文档字符串 – 为 Python 函数编写文档字符串。
- 修复 Python 代码中的错误——查找并修复源代码中的错误。
人工智能的快速采用
软件公司正争先恐后地将人工智能集成到他们的应用程序中。 ChatGPT 周围有一个家庭手工业。 有些人创建了利用其 API 的应用程序。 甚至有一个网站自称是 ChatGPT 提示市场. 他们出售 ChatGPT 提示!

Samsung 是一家看到潜力并加入潮流的公司。 三星的一位工程师使用 ChatGPT 帮助他调试一些代码并帮助他修复错误。 实际上,工程师曾在三个不同的场合将企业 IP 以源代码的形式上传到 OpenAI。 三星允许——一些消息人士称,鼓励——其半导体部门的工程师使用 ChatGPT 来优化和修复机密源代码。 在这匹著名的马被邀请出去放牧之后,三星通过将与 ChatGPT 共享的内容限制在一条推文以下,并调查了参与数据泄露的员工,从而关上了谷仓的门。 它现在正在考虑构建自己的聊天机器人。 (由 ChatGPT 生成的图像 – 对提示的潜在无意讽刺,如果不是幽默的话,“三星软件工程师团队使用 OpentAI ChatGPT 调试软件代码,当他们惊讶和恐惧地意识到牙膏已经从管子里出来并且他们已经将公司的知识产权暴露在互联网上”。)
将安全漏洞归类为“泄漏”可能用词不当。 如果你打开水龙头,那不是漏水。 类似地,你在 OpenAI 中输入的任何内容都应该被视为公开的。 那就是开放人工智能。 它被称为开放是有原因的。 您在 ChatGpt 中输入的任何数据都可能“用于改进他们的 AI 服务,或者可能被他们和/或他们的联盟合作伙伴用于各种目的。” (来源.) OpenAI 确实在其用户中警告用户 指南:“我们无法从您的历史记录中删除特定提示。 请不要在谈话中分享任何敏感信息,”ChatGPT 甚至在其 回复,“请注意,聊天界面仅供演示,不用于生产用途。”
三星并不是唯一一家将专有、个人和机密信息公开发布的公司。 一项研究 公司 发现从公司战略文件到患者姓名和医疗诊断的所有内容都已加载到 ChatGPT 中进行分析或处理。 ChatGPT 正在使用这些数据来训练 AI 引擎并改进提示算法。
用户大多不知道他们敏感的个人身份信息是如何管理、使用、存储甚至共享的。 如果一个组织及其系统受到损害,个人数据被泄露、被盗并被用于恶意目的,人工智能聊天中的在线威胁和漏洞将是重大的安全问题。
人工智能聊天的本质是处理和分析包括个人信息在内的大量数据,以产生相关结果。 然而,大数据的使用似乎背离了隐私的概念……(来源.)
这不是对 AI 的控诉。 这是一个提醒。 这提醒我们应该像对待互联网一样对待人工智能。 换句话说,将您输入 OpenAI 的任何信息视为公开信息。 (还要记住,AI 生成的任何输出都可以进一步转换或用作为未来用户生成答案的模型。)这是 AI 损害知识产权和隐私的一种方式。 另一个争议是人工智能对受版权保护的材料的使用。
人工智能与版权困境
有许多与 AI 合理使用和受版权保护的材料有关的问题。 人工智能能够处理书面文字。 它可以根据特定的写作风格总结、分析、分类甚至创建新的内容。 人工智能是根据内容进行训练的。 我认为它很难避免使用受版权保护的材料。 据我所知,现行法律并未完全解决将受版权保护的内容用于培训的问题。 (图片)
我让 OpenAI 为 Harper Lee 的“杀死一只知更鸟”的第一页打字。 它做了。 所以,我很确定它可以访问受版权保护的文本。 然后它可以创建哈珀李风格的简历。 或者,您可以要求它根据本书的主题创作一首十四行诗。
| 莎士比亚十四行诗
基于“杀死一只知更鸟”的主题 在梅科姆镇,正义似乎是一个梦想, 小童子军和杰姆发现了超越他们年龄的真相。 他们的父亲,阿提克斯,一个高贵的主题 他们的道德指南针引导他们克服恐惧。 汤姆·罗宾逊,一个被诬告的黑人, 否认一个声音,一个公正和公平的审判。 但阿迪克斯为他辩护,并不觉得好笑, 因为真理和正义必须是我们的事。 反舌鸟,纯洁优雅的象征, 无害,它的歌曲带来和平。 但邪恶潜伏在这个小镇的空间里, 正义随着仇恨开始增加而下降。 Harper Lee 的话,对我们所有人的警告, 为正义而战,以免我们倒下。 |
|---|
这不可能与莎士比亚的作品或哈珀李的作品相混淆。 它是变革性的新内容,显然不要与原始内容混淆。 出现了几个问题。 它在什么时候变成转型? 换句话说,原始作品需要更改多少才能被视为新内容?
另一个问题——这同样适用于 AI 创建的任何内容——谁拥有它? 谁拥有内容的版权? 或者,作品甚至可以受版权保护吗? 可以说版权的所有者应该是制作提示并向 OpenAI 提出请求的个人。 围绕即时创作有一个新的家庭手工业。 在某些在线市场上,您可以支付 2 到 20 美元的费用以获得计算机生成的艺术作品或书面文字的提示。
还有人说它应该属于OpenAI的开发者。 这引发了更多问题。 它取决于用于生成响应的模型或引擎吗?
我认为最有说服力的论点是计算机生成的内容不能受版权保护。 美国版权局在 联邦公报,2023 年 XNUMX 月. 其中指出,“由于该办公室每年收到大约 XNUMX 万份注册申请,它看到了注册活动的新趋势,可能需要修改或扩展申请中披露的信息。” 它继续说,“这些技术,通常被描述为‘生成人工智能’,引发了这样的问题:它们生产的材料是否受版权保护,由人类创作和人工智能生成的材料组成的作品是否可以注册,以及什么是寻求注册的申请人应向办公室提供信息。”
“办公室”承认,将一项已有 150 年历史的法律应用于还未满一周年的技术存在一些问题。 为了解决这些问题,版权局发起了一项研究该问题的倡议。 它将就如何解决在人工智能训练中使用受版权保护的内容以及如何考虑生成的内容进行研究并公开征求公众意见。
联邦公报, 有点令人惊讶的是,提供了一些色彩评论并描述了一些与作品的“作者身份”及其版权历史政策相关的有趣案例。 一个被裁定的案件认为猴子不能拥有版权。 在这种特殊情况下,猴子用相机拍摄图像。 法院裁定这些图像不能获得版权,因为版权法提到了作者的“孩子”、“寡妇”、“孙子”和“鳏夫”。 在法庭看来,这种语言排斥猴子。 “该办公室现有的注册指南长期以来一直要求作品是人类创作的产物。”
当 OpenAI 被问及争议时,它说,“是的,在软件和人工智能方面,知识产权法存在灰色地带。 由于技术的复杂性和缺乏既定的法律先例,通常很难确定创作者对其作品拥有哪些权利。 例如,如果人工智能算法是基于小说或现有软件程序,那么谁拥有算法或原创作品的权利并不总是很清楚。 此外,人工智能相关发明的专利保护范围是一个有争议的法律问题。”
OpenAI 在这一点上是正确的。 很明显,美国的版权申请必须具有人类作者身份。 从现在到年底,版权局将尝试解决一些遗留问题并提供额外指导。
专利法与人工智能
围绕美国专利法及其是否涵盖人工智能发明的讨论也是类似的情况。 目前,根据法律规定,可获得专利的发明必须由自然人做出。 美国最高法院拒绝审理对这一概念提出质疑的案件。 (来源.) 与美国版权局一样,美国专利商标局正在评估其立场。 美国专利商标局可能决定使知识产权所有权更加复杂。 人工智能的创造者、开发者、所有者可能拥有它帮助创造的发明的一部分。 非人类可以成为部分所有者吗?
科技巨头谷歌最近也加入了进来。 “‘我们认为,根据美国专利法,人工智能不应被标记为发明者,并且认为人们应该对在人工智能帮助下实现的创新持有专利,’谷歌高级专利顾问劳拉·谢里丹 (Laura Sheridan) 表示。” 在谷歌的声明中,它建议增加对人工智能、工具、风险和专利审查员最佳实践的培训和意识。 (来源.) 为什么专利局不采用使用人工智能来评估人工智能?
人工智能与未来
人工智能的能力,事实上,整个人工智能领域在过去 12 个月左右的时间里发生了变化。 许多公司希望利用 AI 的力量,并获得更快、更便宜的代码和内容所带来的好处。 企业和法律都需要更好地理解技术在隐私、知识产权、专利和版权方面的影响。 (由 ChatGPT 生成的带有人类提示“AI and the Future”的图像。注意,图像不受版权保护)。
更新:17 年 2023 月 XNUMX 日
每天都有与人工智能和法律相关的发展。 参议院设有隐私、技术和法律司法小组委员会。 它正在举行一系列关于人工智能监督:人工智能规则的听证会。 它打算“编写人工智能的规则”。 小组委员会主席参议员理查德布卢门撒尔表示,目标是“揭开这些新技术的神秘面纱并对其负责,以避免过去的一些错误”。 有趣的是,在会议开始时,他播放了一段深度伪造的音频,克隆了他的声音,其中包含根据他之前的言论训练的 ChatGPT 内容:
很多时候,我们已经看到当技术超过监管时会发生什么。 对个人数据的无节制利用、虚假信息的泛滥以及社会不平等的加深。 我们已经看到算法偏见如何使歧视和偏见长期存在,以及缺乏透明度如何破坏公众信任。 这不是我们想要的未来。
它正在考虑一项建议,即根据食品和药物管理局 (FDA) 和核管理委员会 (NRC) 模型创建一个新的人工智能监管机构。 (来源.) AI 小组委员会的一位证人建议,AI 应该像 FDA 监管药品一样获得许可。 其他目击者将 AI 的现状描述为充满偏见、几乎没有隐私和安全问题的狂野西部。 他们将西方世界的机器描述为“强大、鲁莽且难以控制”的反乌托邦。
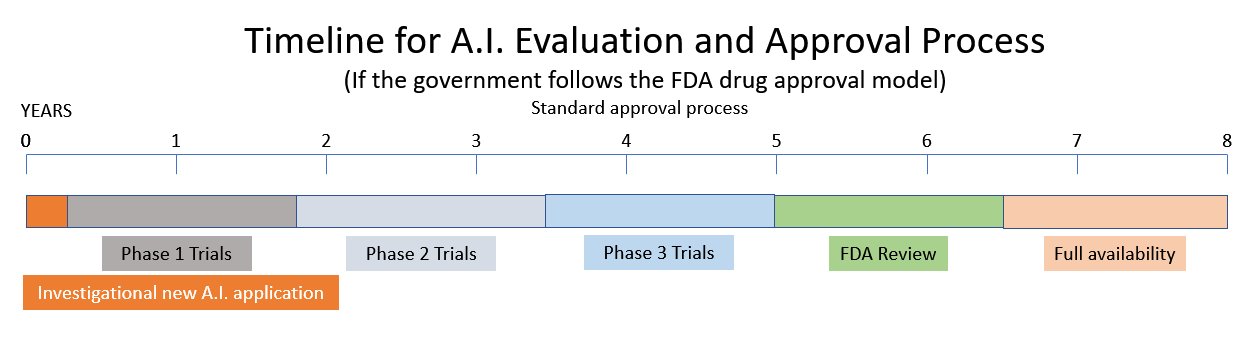
将一种新药推向市场需要 10-15 年和 XNUMX 亿美元。 (来源.) 因此,如果政府决定效仿 NRC 和 FDA 的模式,请期待最近人工智能领域激动人心的创新海啸将在不久的将来被政府监管和繁文缛节所取代。






.jpg){kind=link}